


This week at the Embedded Vision Summit in California we are showcasing our latest Convolutional Neural Network (CNN) object recognition demo. Since launching the original demo at last year’s EVS, the demo has been expanded to include multiple network models and is now implemented using Imagination’s own graph compilation library – IMG DNN.

What are CNNs?
Before continuing, a quick recap: CNNs are a branch of machine learning which attempt to mimic the behaviour of the human visual cortex in order to understand an image, so that specific features can be identified, depending on the application. It’s worth noting that CNNs aren’t limited to visual applications, but that’s what we’ll focus on here. Common real-world visual use cases include facial recognition, and character recognition on vehicle license plates. A CNN consists of a number of layers which perform various operations on an input image to isolate certain features, and outputs some meaningful value. What sets CNNs apart from other deep neural networks (DNNs) is that their layers make use of image convolution filters. In the case of license plate character recognition, the input is the image of the plate, the operations might include edge detections and other convolution filters to extract important features, and the output is the license plate in text form.

Before it can be used, a CNN has to be trained using a training data set. These data sets can be huge – in the above example, the training data might consist of tens or even hundreds of thousands of images of license plates. In simple terms, the CNN is fed this training data along with its expected outputs. If the CNN’s output doesn’t match the expected output, then the CNN corrects itself – adjusting the weights and coefficients used in the network. This process continues until the CNN produces acceptable output for the training data. It is then considered trained and ready to use in the field with new inputs it hasn’t seen before.
The Demo
Our demo takes a live camera feed and identifies the object the camera is pointing at. A camera frame is passed to the CNN, and a label is output on the screen along with a confidence percentage, indicating how sure the network is of its response to the input image. The demo is running under Linux on an Acer R13 Chromebook, containing a PowerVR Rogue GX6250 GPU.
The demo implements three well-known network models – AlexNet, GoogLeNet Inception V1, and VGG-16. Each network has different characteristics, meaning different networks may perform better in different scenarios. The key high-level characteristics here are the number of operations and memory usage, which directly influence the speed and accuracy of the network. All of the network implementations in use in the demo are Caffe models, trained against the ImageNet data set.
AlexNet was the first of a recent wave of new network models, bringing CNNs to the forefront of Deep Learning by widening the scope of the much earlier LeNet – which was limited to character recognition – to learn more complex objects. It is characterised as having reasonably high memory usage, relatively few operations and being less accurate than more recent network models.
GoogLeNet Inception V1 has a significantly smaller memory footprint than other networks. It performs more operations than AlexNet but achieves much better accuracy.
VGG-16 is the most accurate of the three networks in the demo but also has by far the largest memory footprint and number of operations, and so is noticeably slower to produce output than the others.
While it may seem odd to be interested in models that are relatively computationally or memory heavy, it’s important to consider the use cases for each network. There may be applications where accuracy is critical, but new results are only needed very infrequently. Conversely, there may be cases where rapid inference is preferred at the expense of absolute accuracy. Networks such as VGG-16 are also used as benchmarks and stress tests, because of the volume of memory used and operations required.
The above video is showing the GoogLeNet and AlexNet models processing the same set of images. You can see that while they both do a good job, AlexNet does fall short in some cases.
IMG DNN
All of these networks have been implemented using Imagination’s own DNN library, which is included as part of the PowerVR GPU driver. This library is a DNN graph compiler and optimiser tailored specifically for PowerVR. While this demo is about CNNs, this library can be used to accelerate any kind of deep neural network.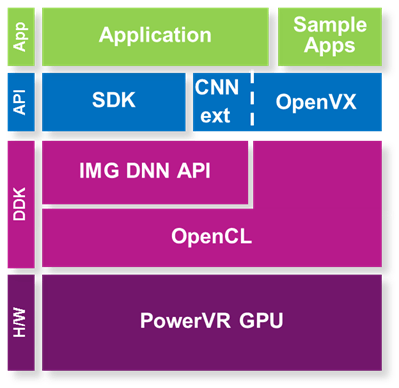
IMG DNN sits on top of OpenCL but doesn’t obscure it, and makes use of OpenCL constructs so it can be used alongside other custom OpenCL code. The library performs low-level hardware-specific optimisations, potentially enabling better-optimised graphs than a custom user OpenCL implementation. The library takes into account the performance characteristics of the underlying PowerVR hardware (e.g. memory bandwidth, number of ALUs) and then looks at the network graph as a whole, in order to give the most optimal results and achieve performance portability across any PowerVR GPU.
Embedded Vision Summit
This demo will be on show at the Embedded Vision Summit in California from 1st to 3rd May. Come along and discuss the demo in person, and learn more about how PowerVR can accelerate your CNNs.
Imagination’s Paul Brasnett is also talking at the summit on the subject of ‘Training CNNs for Efficient Inference‘ and for further reading, take a look at this CNN based number recognition demo, which uses OpenVX with CNN extension.



