

Or: How I learned to stop worrying and ping-pong the queues
In this article, we are referring to the various problems we encountered when it comes to sandwiching compute tasks during graphics processing in Vulkan®. To find out exactly what we’re talking about be sure to read part one first.
The issue outlined there is discussing the use of barriers in Vulkan; specifically, the issue of having a graphics→compute barrier and then a compute→graphics barrier mid-frame. This can severely compromise the ability of the GPU to schedule tasks and introduce mini stalls, hurting performance.
Different solutions have been demonstrated across several resources.
Architectural approach
An “algorithmic” first approach is to interleave the tasks manually: in other words, submit the tasks in the order we want them to execute on the GPU. This will possibly produce the correct results and also provide us with a lot of control. In this case it would mean first submitting a compute task (BN-1) for the previous “logical” frame (note the absence of the early graphics tasks), followed by submitting the early graphics task of the current frame(AN). Then you would you submit a compute/graphics barrier, next submit the late graphics of the previous frame(CN-1) and finally the graphics/compute barrier.
This may produce good results but will compromise our frame’s separation and make maintenance more difficult. It will require doubling a lot of our logical resources because there will be at least a part of code where operations from later frames will need to be scheduled before operations from earlier frames. Also, one additional frame of lag will creep in.
This would look like this:
Frame N: BN-1 → AN → compute/graphics barrier → CN-1 → graphics/compute barrier → Submit N-1
Frame N+1: BN → AN+1 → compute/graphics barrier → CN → graphics/compute barrier → Submit N
This would allow BN-1/AN overlap.
This sounds complicated to do, and it is: calculating operations for more than one frame usually ends up with an awkward amount of book-keeping. However, if the tasks package nicely in this scenario, this would mitigate our problem, at least up to a point. However, it could still break down if we had even more complexity (i.e. a more complex hypothetical compute→barrier→graphics→barrier→compute→ barrier→graphics workload). In any case, for the cost of increasing CPU-side complexity, you could tailor a solution here.
Different queue per-task usage
Another valid solution is to use different queues and submitting different parts of the frame to each: each of early compute, late compute, early graphics, and late graphics is submitted on its own queue, and the tasks connect with semaphores instead of barriers. For example, the VulkanParticleSystem example of the PowerVR SDK takes this approach and submits all compute in its dedicated queue.
This solution has its challenges, but in my opinion, it is better than the frame interleaving, as it allows the GPU to take care of its own problems without messing with the non-API parts of the engine. Also in my opinion, this is the first “real” solution. This would mitigate at least part of the problem, similar to the solution above. Arm is discussing this solution in its community website when discussing compute postprocessing on its own architecture. But again, it is contingent on overlapping some specific tasks and in general requires careful crafting with a lot of semaphores, and has the mixed blessing of making use of queue priorities, which add a small degree of complexity but give you another vector of control. It may also not work exactly as we would want to in the case of multiple interleaved compute/graphics tasks. This solution is very much valid, and indeed it might be a good idea to even combine it with other solutions.
We have found a different solution that we recommend.
A simpler, generic solution: ping-pong queues
We believe we can do things in much simpler and more effective way. To do this, we need to think of the big picture of what we are trying to achieve: we are trying to enable the GPU to interleave work from two consecutive frames without the Vulkan spec getting in the way.
Someone savvy from the Vulkan specification team might now realise the fact that barriers are constructs that always refer to a single queue.
PowerVR (and many other!) devices may expose multiple identical/interchangeable universal queues (graphics+compute and potentially present).
Hence, in this case, what we could do to avoid cross-frame synchronisation, without restructuring the frame at all, would be to submit work for each frame on a different queue. This would allow any work from one frame to be interleaved with any work from the next frame, even with multiple different graphics, vertex, and compute tasks, as they are explicitly executing on different queues and hence not subject to each other’s barriers.
It is as simple as this: you create two identical queues from the same queue family, and then each frame, you submit the work on a different queue than the last. The queue family is important because it allows you to not need to worry about issues such as queue ownership of resources.
So, the frame submission would look like this:
Frame 0: AcquireNextImage → Render 0 (A0) → graphics/compute barrier → Compute0 (B0) → compute/graphics barrier → Render 0′ (C0) → Submit into Queue 0 → Present onto Queue 0
Frame 1: AcquireNextImage → Render 1 (A1) → graphics/compute barrier → Compute1 (B1) → compute/graphics barrier → Render 1′ (C1) → Submit into Queue 1 → Present onto Queue 1
Frame 2: AcquireNextImage → Render 2 (A2) → graphics/compute barrier → Compute2 (B2) → compute/graphics barrier → Render 2′ (C2) → Submit into Queue 0 → Present onto Queue 0
Frame 3: AcquireNextImage → Render 3 (A3) → graphics/compute barrier → Compute3 (B3) → compute/graphics barrier → Render 3′ (C3) → Submit into Queue 1 → Present onto Queue 1
… and so on.
So, does this help us? And, if it does, why does it?
It does. The barrier between BN (compute of current frame) and CN (late graphics of current frame) would prevent CN to start before BN finishes, but it would not prevent AN+1 (early graphics from the next frame) to start, as it is submitted on a different queue than the barrier. (As a bonus, since the queues are different, AN+1 is not necessarily compelled to be ordered with regards to CN).
This technique solves the heart of the problem: application-imposed barriers that were intended to wait for hazards in a single frame, do not cause waits between tasks between subsequent frames. I found this quite pleasing aesthetically, and it is by far the simplest solution to implement – as long as you have a universal queue family with more than one queue, you can use a single counter (even Boolean) and swap every frame, and at that point, no further modifications are required: as long as we ensure our CPU resources are correctly managed (same as with a single queue), no additional synchronisation requirements are imposed.
In short, because each successive frame is submitted on a different queue, the GPU is free to schedule the tasks between the frames in parallel to each other, and the expected result is (CN+1) beginning to execute right after (AN) finishes. This ensures that the renderer and its corresponding schedulers are always busy and that the compute in the middle does not serialise the frame.
—————–
Compute workload: B0 B1 B2 B3 B4 B5
Graphics workload: A0 A1 C0 C1 A2 A3 C2 C3 A4 A5 C4 C5 …
Or (basically identical effect) this:
Compute workload: B0 B1 B2 B3 B4 B5
Graphics workload: A0 A1 C0 A2 C1 A3 C2 A4 C3 A5 C4 C5 …
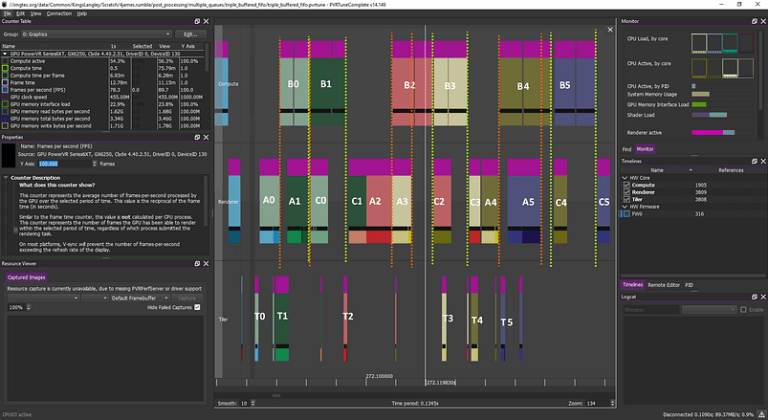 SOLUTION: By using multiple queues, the early fragment tasks of the next frame can be scheduled right after the early tasks of the previous frame, overlapping with the compute tasks for excellent efficiency gains
SOLUTION: By using multiple queues, the early fragment tasks of the next frame can be scheduled right after the early tasks of the previous frame, overlapping with the compute tasks for excellent efficiency gains
This may seem complicated at first glance, but it is simpler than it looks. In any case, this graph tells us that the GPU is processing compute of one frame (N) at the same time as early graphics of the next frame (N+1) or late graphics of the previous frame.
The case where everything would be perfectly packed is “rather impossible” to get, and it is not even necessary to get this level of packing. However, you should be getting something similar, with compute scheduled together with vertex/fragment tasks, allowing the USCs to be loaded to capacity as much as possible.
Another case where this could apply
In general, it is a good idea to use this technique in cases where you have any barriers, not just graphics/compute/graphics. It will not hurt performance in any case, and it will allow more flexibility to the scheduler in all cases. The scheduler might not need the extra flexibility, but it will not hurt performance in any case and the extra complexity is trivial.
Any kind of barrier, including graphics/graphics, has the potential to compromise the ability of the GPU to schedule work from different frames together and cause stalls (and, by the way, this is a very important reason to think about your barriers: if it is possible to use subpass dependencies instead of barriers). The compute example is quite important because even though they share the execution cores, graphics and compute on PowerVR work on different data masters so there is always some parallel work to be performed, so we always want them to overlap if at all possible. However, interleaving even just graphics work from different frames will usually allow you to get more overlap between vertex and fragment tasks and ensure better saturation of the GPU.
So, any case of barrier is a potential case of bubbles, hence a potential candidate for using multiple queues.
Caveats and limitations: How I learned to stop worrying and use multiple queues
We have not been able to identify any serious disadvantage. There is no overhead in using different queues among different frames. The only limitation we have identified is the obvious one: multiple graphics+compute queues must be supported on the same queue family, and all PowerVR devices support that.
The only other potential problem we were able to identify was ensuring correct presentation order. However, the swap chain object itself will ensure this as images are presented in the order vkQueuePresent is called for FIFO and Mailbox presentation modes. For other modes (e.g. Immediate) you might need to ensure that the present operations are correctly synchronised to happen in order; however, this should also be trivial to do.
Finally, if a device only exposes a single presentation queue, you might modify as follows and only present on a single queue:
Frame 0: AcquireNextImage → Render 0 → Record graphics/compute barrier → Compute0 → compute/graphics barrier → Render 0′ → Submit into Queue 0 → Present onto Queue 0
Frame 1: AcquireNextImage → Render 1 → Record graphics/compute barrier → Compute1 → compute/graphics barrier → Render 1′ → Submit into Queue 1 → Present onto Queue 0
Frame 2: AcquireNextImage → Render 2 → Record graphics/compute barrier → Compute2 → compute/graphics barrier → Render 2′ → Submit into Queue 0 → Present onto Queue 0
Frame 3: AcquireNextImage → Render 3 → Record graphics/compute barrier → Compute3 → compute/graphics barrier → Render 3′ → Submit into Queue 1 → Present onto Queue 0
… and so on.
This not only takes advantage of the parallelism but also ensures that drivers with an “idiosyncratic” implementation of the swap chain would not run the risk of presenting frames out-of-order.
In short, we have not found a reason not to use this technique. If you find one, please comment back.
An important performance note
It is important to remember that PowerVR scheduling does not work like CPU threads where you have expensive context switches and saving to main memory – if the scheduler is executing two tasks in parallel on the same USC, switching between them in most cases a zero-cost operation, so every time an operation needs to wait (e.g. for a memory access), the scheduler can switch to another task and hide the latency of the memory operation. This is an important part of where our performance gains come from.
This is something we feel should be clarified. This technique is not mainly about filling up with work different hardware parts that would otherwise be idle; what we are trying to do is instruct the drivers correctly in how to schedule our work, to reduce overhead and hide latency. PowerVR is a unified architecture, so vertex, graphics, and compute tasks ultimately execute on the same USCs. Unlike the early days of graphics where different vertex and fragment shader cores would execute individually, 100% gains in performance are not to be expected. We are not trying to fill idle cores; all USCs are running whenever the GPU is not idle unless something really strange is going on.
Finally, a situation like this may also be encountered with graphics-only workloads where the barriers again may prevent overlaps among different frames.
Future work
This technique can and will work in cases where you wish to submit different work to different queue types/families. An important disclaimer here is that this technique does not replace the potential benefits of using different queues for different workloads of the frame – as in this and other articles discussed, using different dedicated queues (especially utilising different queue priorities to minimise frame lag).
So, in these scenarios, you can use the same logic – the only difference is that instead of multiplying the one queue into two, you would multiply all (or most) queues where you use barriers. This may not be all the queues, so this cannot be substituted for common sense and good designs. In some architectures, you might be using three different queues, and only need to multiply and ping-pong one or two of them. Most important is to multiply at least one queues next to your barrier.
For example, assuming a hypothetical core with (let’s assume) a single dedicated compute queue alongside multiple universal queues, this technique could still be relevant. In fact, it could be a most interesting scenario to have multiple sets of different queues with different priorities and swapping the sets between frames – this could provide with an amazing amount of fine-control and flexibility. This scenario might look like this:
(Queue C2 here is a dedicated compute queue and Queues 0 and 1 being the Universal queues we are multiplying):
Frame 0: AcquireNextImage → Render 0 → Submit into Queue0 → Semaphore to queue 2 → Compute0, Submit into Queue C2 → Semaphore to Queue 0 → Render 0′ → Submit into Queue 0 → Present onto Queue 0
Frame 1: AcquireNextImage → Render 1 → Submit into Queue1 → Semaphore to queue 2 → Compute1, Submit into Queue C2 → Semaphore to Queue 1 → Render 1′ → Submit into Queue 1 → Present onto Queue 1
Frame 2: AcquireNextImage → Render 2 → Submit into Queue0 → Semaphore to queue 2 → Compute2, Submit into Queue C2 → Semaphore to Queue 0 → Render 2′ → Submit into Queue 0 → Present onto Queue 0
Frame 3: AcquireNextImage → Render 3 → Submit into Queue1 → Semaphore to queue 2 → Compute3, Submit into Queue C2 → Semaphore to Queue 1 → Render 3′ → Submit into Queue 1 → Present onto Queue 1
Frame 4: AcquireNextImage → Render 4 → Submit into Queue0 → Semaphore to queue 2 → Compute4, Submit into Queue C2 → Semaphore to Queue 0 → Render 4′ → Submit into Queue 0 → Present onto Queue 0
Again, the multiple graphics queues here are necessary to allow the first render of a successive frame to be scheduled before the second render of the current frame.
Conclusion
We have presented you with a very complete and generic solution to a very common and difficult real-world problem. Use multiple queues per frame whenever you can, and you can easily get near-magical performance gains for next to no risk and complexity. We hope this helps you with your projects! If you are helped by this technique, feel free to share your story below!
We are using this technique in many of our demos in the PowerVR SDK, but we were inspired and mostly used it while writing the postprocessing demo.
.png)


