


Vulkan synchronisation scenarios: the use case
In modern rendering environments, there are a lot of cases where a compute workload is used during a frame. Compute is generic (non-fixed function) parallel programming on the GPU, commonly used for techniques that are either challenging, outright impossible, or simply inefficient to implement with the standard graphics pipeline (vertex/geometry/tessellation/raster/fragment). In general, compute provides near-absolute flexibility in implementing techniques. However, this generality introduces other challenges: there are much fewer assumptions that the GPU can make with regards to synchronising the rendering tasks, especially as we try to optimise and keep the GPU saturated with work.
Without going into too much detail, keeping the GPU occupied is crucial; in fact, it is the single most important performance factor. It is virtually pointless to try to micro-optimise an application if you have times where the GPU is not doing anything – or is under-utilised – while our framerate target is not yet achieved.
On the other hand, this situation reverses when our maximum framerate target is hit: if we are already rendering all that we need to render within our allotted minimum frame time – in other words displaying as many frames as we need – we should allow the GPU to go idle so that it spends less power and emits less heat. However, this is not an excuse to not synchronise correctly; small work-spikes will not be optimally absorbed if the synchronisation is incorrect and can cause unnecessary FPS fluctuations.
To synchronise in Vulkan®, conceptually, we need to express dependencies between different operations. Vulkan is quite flexible and powerful at this. However, this flexibility can be a double-edged sword; the task can become daunting as synchronisation gets complicated and verbose, and it is not a simple task to reason about what the optimal path is. The tools used for synchronisation are barriers, events, semaphores, and fences; each enforcing the order of operations in a different scenario. The most common and lightweight one is the barrier, which simply enforces an ordering of specified types of command before and after itself on the GPU.
Essentially, the usual way to use a barrier is to express a source and destination dependency. Translated to English, this would express something such as the following:
“For all graphics commands that have been recorded up to this point; ensure that at least their fragment step has executed; before beginning to execute the vertex step; of graphics commands recorded after this point”
As an example, this might be a colour attachment of one pass being used as an input attachment on another pass (disregard the fact that this particular case might better be expressed with subpass dependencies – this is just an example).
When the command buffer containing this barrier is then submitted into a queue, it will take effect for all commands in that queue (this is a hint for later). If we needed this effect across different queues, the correct primitive would be a semaphore. If we needed to synchronise to wait for events on the CPU, we would use fences or events. If we wanted arbitrary synchronisation between CPU/GPU, we would use events.
In our specific use-case, the barrier we will be using is as follows:
“For all compute commands that have been recorded up to this point; ensure they have finished executing; before starting the vertex step; of graphics commands recorded after this point”. We will refer to this as a compute→graphics barrier.
“For all graphics commands that have been recorded up to this point; ensure their pixel stage has finished executing; before starting to execute; compute commands recorded after this point”. We will refer to this as a graphics→compute barrier.
First things first: The weapon of choice
When dealing with any performance tuning on PowerVR platforms, your best friend is PVRTune. PVRTune is our GPU profiling application and provides an absolute cornucopia of information. This includes all tasks executing on the GPU in real-time, a host of hardware counters, load levels, rates of processing, and many more. We can’t stress this enough – PVRTune should always be the first and last stop for profiling applications on-device. It supports all PowerVR platforms, so be sure to download PVRTune and all the other free PowerVR tools.
A note on the diagrams
For this article, in all our examples below, for simplicity, we will ignore the tiler tasks (marked in the diagrams as TN).
Tiler here refers to the same processing stage as vertex tasks and the two terms can be used interchangeably.
Renderer refers to the same processing stage fragment/pixel tasks and again the terms can be used interchangeably.
In general, what we are referring to in this article can be extrapolated to the vertex tasks, but vertex tasks are usually much easier to handle as they tend to naturally overlap mid-frame compute tasks, which are the most difficult circumstances discussed here and normally have dependencies with the fragment stages.
However, if you have compute→vertex (or even vertex→compute) barriers, similar situations with exactly the same solutions could happen with vertex tasks.
A note on multi-buffering
In desktop PCs, double-buffering (using two framebuffer images in your swap chain) seems to be the norm nowadays.
However, double-buffering will not actually allow you to overlap enough work from different frames on mobile devices. PowerVR is a tile-based deferred rendering architecture and can make great use of the ability to process multiple frames in parallel. Without going into too much detail, based on the Vulkan specification, it is not normally possible to render to the framebuffer image that is currently being presented on screen. This means that at any given point in time, the GPU can only be actively rendering to the “free” image (the back-buffer).
It is thus highly recommended to create swap chains using three framebuffer images, especially in cases where vertical synchronisation (Vsync) is enabled (or forced, such as on Android platforms). The technique is then commonly called triple-buffering and can allow for much higher performance than double-buffering.
The downside of triple-buffering is that it introduces an extra frame of latency compared to double-buffering. This can be unwanted is some very latency-sensitive scenarios (competitive gaming in high-paced FPS games on desktop computers), but is very rarely an issue on mobile devices.
However, this is not an article on multi-buffering, so we will not go into further detail, but suffice it to say that this article assumes that you are using three framebuffer images to leverage this parallelism. Triple-buffering is the default if you are using the PowerVR SDK and potentially some other solutions.
Trivial cases
A trivial (yet uncommon) case might be for the compute and the graphics workloads to be “embarrassingly parallel”: completely independent of each other and able to be executed completely in parallel. This would happen if we had some unrelated tasks in each frame, such as rendering two different workloads for two different screens that do not interact with one another. No barriers (or other sync primitives) would normally need to happen between those, so the GPU can and will schedule them in parallel.
In the API side, the calls would look like this:
DispatchCompute → Draw → Present
In PVRTune, the compute and the graphics tasks might look like this:
(Numbers denote tasks from different frames)
—————–
Compute workload: B0 B1 B2 B3…
Graphics workload: A0 A1 A2 A3…
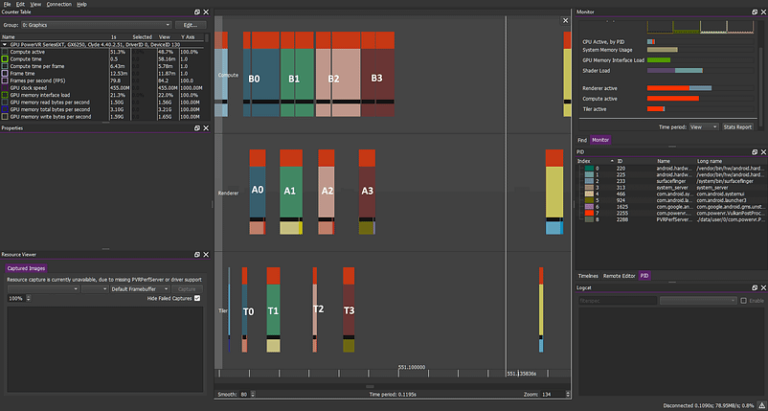 An unusually trivial workload. No sync primitives prevent the overlap of different tasks. This is trivial and a rare occurrence.
An unusually trivial workload. No sync primitives prevent the overlap of different tasks. This is trivial and a rare occurrence.
This can provide substantial benefits: By having more work to schedule in and out, the GPU can hide latency and provide a good performance benefit versus executing these tasks one after the other. However, this “embarrassingly parallel” case is not one of particular interest here, and not all that common. However, it highlights a principle that is useful but not always obvious: only synchronise as much as you need to and no more.
Easy cases
Such a case is uncommon, and we could say uninteresting. Something more common is a compute workload that needs to happen before a graphics workload. This could be some kind of vertex processing, compute culling, geometry generation, or any other work required later in the frame. The data would usually be required in the vertex shader. In this case, we will need to insert a vkCmdPipelineBarrier between the vkCmdDispatchCompute and the vkCmdDrawXXX, in order to implement this happens-before relationship. The calls would look like this:
DispatchCompute → Barrier (source:compute, destination:graphics/Vertex) → Draw → Present
Or it could be the exact opposite, such as performing some compute post-processing. However, that would mean writing directly into the framebuffer with compute, which is normally not ideal: the fragment pipeline is much more optimised for writing to the framebuffer, with numerous benefits such as framebuffer compression.
Draw → Barrier (source:graphics/fragment, destination:compute) → DispatchCompute → Present
One might wrongly expect something like this to happen – and indeed if we only double-buffer or make some kind of over-synchronisation mistake, we might end up with that.
If we double-buffer instead of triple-buffering, we will need to wait for Vsync in order to continue rendering, hence a lot of parallelisation may be lost.
—————–
Compute workload: B0 B1 B2 B3 B4…
Graphics workload: A0 A1 A2 A3 A4…
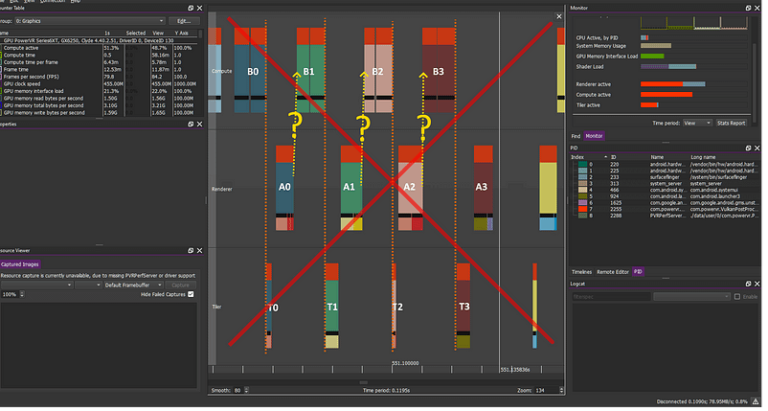 BARRIER compute->Vertex(orange dotted line) correctly prevents AN/BN overlap – Other factors prevent AN/BN+1 overlap
BARRIER compute->Vertex(orange dotted line) correctly prevents AN/BN overlap – Other factors prevent AN/BN+1 overlap
NOTE: This diagram is only pathological with the assumption that the following are true:
- We are using triple buffering
- Vsync is not enabled OR we have not hit maximum fps for the platform
If we are correctly synchronised and at the max Vsync fps (usually 60fps), this case becomes perfectly valid: if there is not enough work to be done, the GPU can and will work less hard, or even go idle, saving power, and the tasks will usually naturally serialise like this. This is valid and very much desirable in these cases. The turning point here is that this should not happen with an application that is running below maximum FPS.
In this case, what we would expect – and what normally happens if we triple-buffer and do not over sync – is much better overlap. The GPU should be able to schedule the pixel operations of one frame (N) with compute operations of the next frame (N+1), as normally no barrier will exist to prevent that. As noted, we need this kind of parallelism for maximum performance.
Compute workload: B0 B1 B2 B3…
Graphics workload: A0 A1 A2 A3…
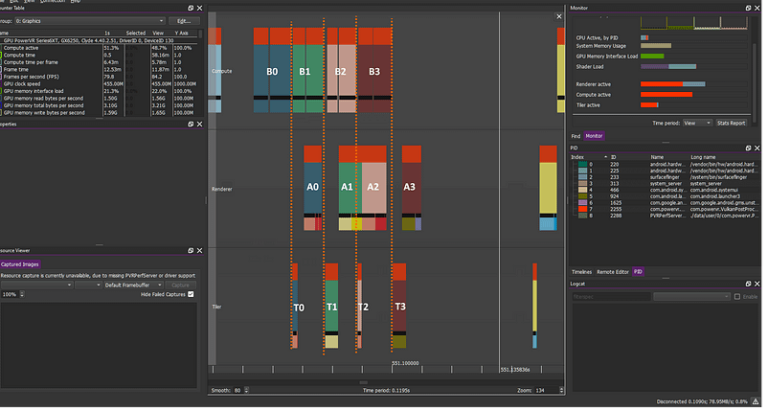 Compute before graphics. BARRIER compute-Vertex(orange) correctly prevents AN-TN/BN mashup but allows BN+1/TN-AN overlap.
Compute before graphics. BARRIER compute-Vertex(orange) correctly prevents AN-TN/BN mashup but allows BN+1/TN-AN overlap.
—————–
We need our objects ready before we draw them. In many cases though, we do not need the previous frame’s rendering to render subsequent frames. Hence, in those cases, the GPU is free to allow BN+1/AN overlap and pack things nicely for a nice performance boost.
More complex, pathological cases
Unfortunately, as usual, things are not that simple. As you move towards advanced multiple-pass pipelines, our rendering tends to be more complicated than that. Even after we perfectly order our operations correctly, we will very commonly end up with an operation where a compute dispatch is sandwiched in between graphics operations. For example, we might be using a compute in the middle of the frame to calculate some optimised Blur values before using a fragment shader to do further post-processing and UI compositing for the screen.
A bird’s eye view of a simple version of this draw process would look like this:
Draw → Barrier (source:graphics/fragment destination:compute) → DispatchCompute → Barrier (source:compute, destination:graphics/Vertex) → Draw → Present
These cases can be rather problematic, for reasons that will become apparent shortly.
A single frame’s tasks, in this case, look like this:
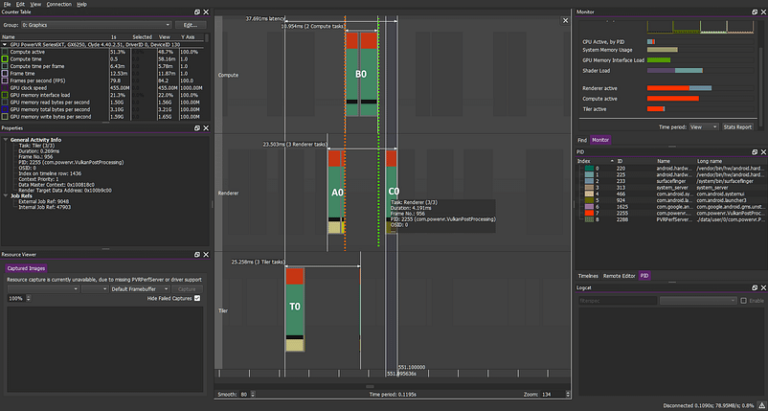 Graphics→compute barrier in orange, compute→graphics barrier in green.
Graphics→compute barrier in orange, compute→graphics barrier in green.
Looking at the previous example, you should hope, at this point, that your A1 should be sandwiched between A0 and C0, overlapping with B0.
Unfortunately, if do basic synchronisation with the barriers above “correctly”, that is not what you will get. You will get this instead:
compute workload: B1 B2 B3 B4 B5
graphics workload: A1 C1 A2 C2 A3 C3 A4 C4 A5 C5 …
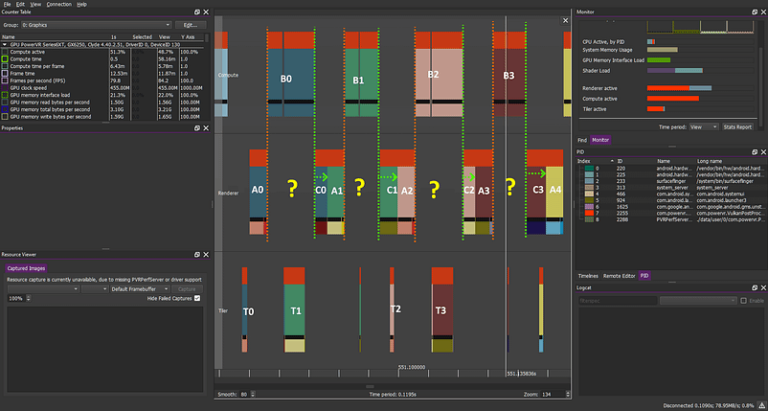 Unfortunate, but common. Nothing at all overlaps with the mid-frame compute tasks… Barrier graphics→compute (Orange) prevents CN from overlapping with BN+1 and Barrier compute→graphics (Green) prevent AN+1 from overlapping with BN
Unfortunate, but common. Nothing at all overlaps with the mid-frame compute tasks… Barrier graphics→compute (Orange) prevents CN from overlapping with BN+1 and Barrier compute→graphics (Green) prevent AN+1 from overlapping with BN
So, we see that early fragment tasks of one frame are practically completely displaced after the entire previous frame.
But why?
Looking at the workload above, looking at the barriers the answer should become reasonably apparent:
The (orange) barrier between A and B can be read in English as: “No compute task; that gets scheduled after AN is scheduled; is allowed to begin executing; before AN finishes executing”. Hmm… this looks reasonable.
The (green) barrier between B and C reads: “No graphics task; that gets scheduled after BN is scheduled; is allowed to begin executing; before BN finishes executing”. This barrier also makes sense as we need CN to start after BN finishes.
But then we would also like AN+1 (which is also a graphics task) to be scheduled as soon as possible; preferably as soon as CN starts. However, the barrier between BN/CN disallows this, causing everything to cascade: AN+1 is displaced after BN but because CN is already scheduled, it displaces AN+1 even further (different pixel tasks cannot overlap with each other), leading to a full serialisation of all the tasks.
In short, the compute/graphics barrier disallows early graphics tasks of the next frame from executing at the same time as compute tasks (green arrows).
This is bad news. The USCs (Unified Shading Cluster, the heart of PowerVR GPUs where all math and computations happen) in this case is very much at risk of being underutilised, and there has to be at least some amount of overhead in the communication between these tasks. The less work that can be scheduled, the less the chance of good utilisation. Additionally, compute and graphics tasks are commonly different in their makeup, with one being memory/texture limited and the other ALU/math limited, and are very good candidates for being scheduled at the same time. Additionally, if all tasks are serial, tiny gaps may also be commonly introduced between them (pipeline bubbles) and finally v-sync will compound this problem further. All these factors can add up to a hefty performance difference, and we have seen a lot of variation in this area; while your mileage may vary, numbers in the order of 20% are uncommon. The “low” cases had a 5% potential gain through better overlap, and we have seen as high as 30% performance gains in a real-world application.
So to summarise: we would like early graphics from the next frame (AN+1) to be able to be scheduled before late graphics of frame N (CN) so that they execute in parallel with compute of the current frame (BN) in order to achieve much better GPU utilisation.
This is an idea of what you can encounter when dealing with synchronisation in Vulkan. The possible solutions are examined in our follow-up post.
.png)


