

Welcome to the last blog post in the series! You might notice that it’s a bit late – this has been sitting mostly complete on my account for months, but with the Vulkan release taking up a lot of my time, I’m afraid it got neglected! Well, finally we’ll be looking at why Vulkan is a better fit to hardware than previous generation APIs, and I’ll be diving into some of the details of our own PowerVR GPUs to give you some concrete examples.
OpenGL ES
First, let’s consider the current leading API and why problems exist today. OpenGL ES itself is over 12 years old, and the API it’s enormously based on, OpenGL, was designed over 23 years ago. The hardware that OpenGL was originally designed for is a far cry from the variety of hardware you see today.
The state machine
OpenGL is a big, global state machine, and every operation takes into account a various pieces of current state, such as blend modes, current shaders, depth test information, etc. Almost everything looks like it’s a simple on/off switch or lever that can be changed at will with no real consequences – it’s just a function call, right? This is simply not true for modern hardware – for instance, a lot of state will actually be translated to shader code.
I’ve already mentioned that shader patching is problematic with regards to hitching and render-time CPU usage, in my High efficiency on mobile post. There’s another problem which I didn’t previously mention though – inefficiencies in the shader itself. If state has to be patched onto a shader, it happens post-optimized compilation, meaning that it’s effectively just tacked on to the rest of the shader. If the state was known at compilation time, it could’ve been optimally compiled in, avoiding a few instructions. A driver might do a background recompile to combat this, but that is a problem in and of itself (it costs additional CPU time).
Implicit synchronization
OpenGL ES assumes a lot of things implicitly synchronize with each other. Only with the recent introduction of fences, compute shaders and side effects has there been anything that is assumed to work asynchronously in any form. Large portions of the API just work – when in actual fact this boils down to a lot of resource tracking, cache flushing and dependency chain construction behind the scenes.
A driver is unlikely to be able to detect with pin-point accuracy exactly which dependencies you have – they need to be conservative in order to still be a functional OpenGL ES implementation. This means inevitably that caches will be flushed unnecessarily, or work will be serialized unnecessarily – in other words, the hardware is doing more work than it needs to.
Immediate mode
Commands specified in OpenGL ES are assumed to execute, start to finish, in the exact order they were specified. A single command, such as a draw call, is treated as an single, whole unit of work, with each being queued up on the GPU as it is specified. This behavior is known roughly as immediate mode execution – every piece of work specified is in some fashion immediately sent to the GPU for processing.
Immediate Mode Rendering (IMR) architectures mapped quite well to this way of thinking in the past, but modern IMRs tend to batch work up in order to increase performance.
Tile-Based Renderers (TBRs) or Tile-Based Deferred Renderers (TBDRs) have never really worked this way, and they’re by far the most prolific GPU architecture types in existence today: for these types of architecture, the main unit of work is much larger – something most easily explainable as a render pass – a collection of draw calls all targeted at the same framebuffer.
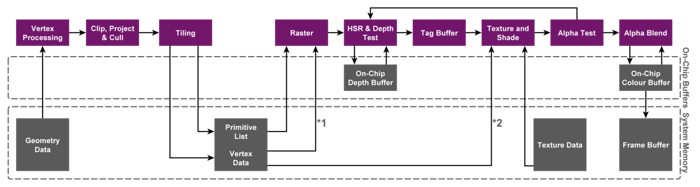
TBRs and TBDRs both have two-stage rendering, with an early phase that processes geometry and sorts it into screen-space tiles. The second phase rasterizes each of these tiles, keeping an entire tile’s worth of framebuffer completely on-chip – saving a lot of bandwidth which is a big win on mobile. Rys Sommefeldt did a more detailed write-up on this here if you’re interested.
The key thing is that at the rasterization phase, a draw call is no longer meaningful – a single draw call may result in rasterization tasks across many tiles, with each tile consisting of work from multiple draw calls. If something causes a flush between draws, it splits the entire render up, requiring two lots of tiles to be rendered. At the start and end of each tiling pass, framebuffer data must be loaded into tiles and then subsequently stored – do this enough times and you start to lose the benefit of having a tile-based architecture, which is trying to avoid exactly this bandwidth.
In any case, modern hardware likes to batch work together, and actually submitting an individual draw would lead to inefficiencies. There are a number of operations in OpenGL ES that force a driver to do this submission, and not all of them are obvious. In the case of a TBR or TBDR, this results in a lot of unnecessary bandwidth that the driver is powerless to do much about.
Vulkan
I may have painted a pretty dreary picture of OpenGL ES – it’s not exactly the end of the world – otherwise we wouldn’t have such wonderful graphics content on mobile today.
However Vulkan does do a heck of a lot better than even a highly optimized OpenGL ES driver ever could. I’ve previously mentioned that Vulkan is explicit and requires a lot of information from an application – all of which is to ensure that Vulkan works smoothly on everyone’s implementations, with not large costs that are invisible to the user.
Pipelines
Vulkan assumes that almost all state is going to be re-used, and can thus be much more static than OpenGL ES makes it seem. Pipelines take most of that previously dynamic state, and provide it along with a shader to be compiled together all at once. This means that anything previously requiring shader patching can now just be compiled in ahead of time. Having this information at compile time means an fully compiled and optimized set of shaders and state that can be immediately used by a draw call, without any need to patch things together during the render loop.
In many cases, an application might only use a shader with one or two sets of state – which keeps the cost fairly low. In some cases though, a lot of different state setup is required; which can result in a huge number of pipeline objects. Whilst Vulkan does little to reduce the number, the actual time taken to compile the whole set of these shaders should be comparable (or potentially faster) by making use of pipeline caches. Pipeline caches are an object that can be passed alongside creation info when creating a set of pipelines, and cache useful information or compiled state and shaders that a pipeline might require. If two pipelines both have the same shader but slightly different state – there’s a good chance that the cost of creation and compilation will be much less than trying to compile them both separately.
Pipelines on PowerVR GPUs
Let’s take blend state as an example – it’s a relatively well known fact that we do not have fixed function hardware for blending. We simply don’t need it – our on-chip storage is fast enough that it’s simpler to just blend directly in our shader cores. Subsequently, setting a blend mode in OpenGL ES results in a set of instructions representing that blend being patched to the end of the current shader.
As I hinted at earlier, shader patching can introduce inefficiencies. Shader analysis shows that for blending it’s usually not too bad, we’re generally only talking one or two instructions. That might not sound like much on its own, and it’s not really, otherwise we’d be rethinking our strategy here – but it does add up. Vulkan instead gives us all of this information at pipeline creation time – allowing us to optimally fold those instructions in before compilation, resulting in leaner shader execution. Other bits of state like the framebuffer format and vertex layout fall into similar categories for us (and more niggly and inobvious bits of state do exist).
Explicit synchronization
There is significantly more control over synchronization between operations than possible in any other graphics API. Memory and execution dependencies are described with a set of very fine-grained what, when, where and how information:
- What objects and operations are involved in the dependency
- When a dependency starts and ends
- Where in the pipeline a dependency is generated (e.g. vertex shading), and where it must be fulfilled (e.g. fragment shading)
- How an image is going to be used on each side of a dependency
All of this information allows a driver to build up a very comprehensive dependency chain, and if an application expresses dependencies perfectly – then only the caches that absolutely need to be flushed and operations that absolutely need to be completed will be waited for.
Explicit synchronization on PowerVR GPUs
On a tile-based architecture, work is split into two parts – the geometry tiling phase, and the rasterization phase. In OpenGL ES, there’s only ever fairly heavy handed synchronization – fences, implicit synchronization, and memory barriers. There’s no way to express that only something in the rasterization phase needs to wait, or that only waiting on the tiling phase is required – either the driver has to work it out via heuristics, or a full synchronization event needs to take place – which seriously harms performance. We typically use a lot of heuristics to make this work in OpenGL ES, but that comes at the cost of often being too conservative, potentially reducing performance compared to what it otherwise could be.
In Vulkan, we can use the pipeline stages described for each synchronization event to decide exactly which hardware phases to execute. If only a fragment stage needs to wait on an earlier event, we can execute the tiling phase for a huge set of draw calls ahead of time to get a head start, and a performance boost in the process. Equally, if a task only needs to wait on the tiling phase, we can signal that task to execute before any rasterization has started. Both of these scenarios result in a shorter length of latency between tasks, and reduces unnecessary idle time on the GPU by allowing overlap of multiple tasks.
Command buffers and hardware queues
Vulkan uses a deferred command submission model – draw calls are recorded into a number of command buffers, then the application submits those buffers to the hardware as a separate operation. This allows implementations to have knowledge about a large portion of the scene in advance, and gives an opportunity to add appropriate optimizations to the submission, which would’ve been difficult to achieve in OpenGL.
The separate hardware queues map very well to modern GPUs – which typically have one or more front-end queues that can deal with command input. Exposing these queues fairly explicitly gives applications a view on the underlying hardware that’s otherwise not there. For instance, if a GPU has a single front-end for graphics commands – it should only expose one graphics queue in the API. Queue submissions are externally synchronized, so that drivers don’t have to take a lock when dealing with multiple threads, and since there’s a close mapping to hardware, queue submission is a relatively inexpensive operation.
Command buffers and hardware queues on PowerVR GPUs
PowerVR runs in a different order to what you might expect from an immediate rasterizer – as discussed above. To actually get the required efficiency out of our hardware it’s important that operations are queued in a particular way (rather than just submitting vertex and raster tasks immediately). In Vulkan, all the dependencies are explicitly laid out ahead of time by the application in the command buffer recording. When a command buffer is recorded, our implementation has the opportunity to determine the most efficient order of operations and submit work appropriately – work that had to be done on-the-fly in OpenGL. As we can figure this out in advance, a command buffer with draw calls in it can be baked into tiling tasks and rasterization tasks that are directly consumable by the hardware.
When these command buffers are submitted to a queue, our implementation of that function is as simple as kicking those generated tasks to the hardware with any semaphores the application provides. It’s not quite a 1:1 mapping of hardware front-ends to API queues for us, as the Vulkan graphics queue is represented by two hardware front-ends (tiling and rasterization). The distinction between these two parts of the hardware is adequately expressed by other parts of the API though, such as render pass objects and the detailed synchronization model.

Render Passes
Render passes group a collection of rendering commands into well defined chunks. They’re not dissimilar from a command buffer in that sense, which is somewhat deliberate, as render passes are the effective unit of work on a tile-based architecture. Commands that could cause a mid-frame flush on a tiler are explicitly disallowed inside a render pass. Draw calls and a few other select commands are only allowed within a render pass, as a tiler needs the information the render pass provides in order to run effectively.
Render passes consist of multiple sub passes, each of which is able to communicate information to subsequent sub passes by means of data local to a given pixel location. Each sub pass defines the load and store operations which takes place on the attachments it uses, execution dependencies on other sub passes, and a list of attachments that are expected to be read from previous passes or preserved.
By using sub pass communication, an application can do simple post-processing techniques such as colour grading or vignetting. Perhaps more interestingly, if an application is using a deferred shading technique, it’s possible (and highly recommended!) to express the G buffer in terms of sub pass dependencies and input attachments.
Attachments don’t even need to be allocated in many cases if they’re only used as intermediates – a lazily allocated memory type exists in Vulkan, and the concept of transient attachment usage. Any attachment that is only going to be used during a render pass (i.e. not loaded from external sources or stored at the end of rendering) can be tagged as being transient, which then allows the lazy allocation strategy for memory objects bound to it. Lazily allocated memory objects may not immediately have any actual physical memory backing when they are first created – they may be completely empty, partially allocated, or fully allocated – depending on the architecture. In most situations, they should remain in their initial state for the lifetime of the object, but if for any reason the implementation needs to allocate more of that memory, it can do so as a late binding operation. The maximum size of that memory object is known ahead of time, and it’s possible to query the current memory commitment for these memory objects.
Render passes on PowerVR GPUs
As I mentioned above, render passes disallow anything that would cause a mid-frame flush on a tiled architecture. This is certainly true for us, and by having the render pass explicitly describe the start and end of rendering and load/store operations for each sub pass, PowerVR GPUs are able to operate with minimal bandwidth – only writing out attachments needed after the render pass completes.
Sub passes dependencies don’t allow anything that definitely causes a flush during rasterization on our architecture either – which means that we have the potential to combine multiple sub-passes, dependencies and all, into a single render pass. The upshot of this is that there’s no stopping and starting of rendering, and intermediate attachments that aren’t explicitly stored don’t need to be written to memory – they can stay in tile memory. Input attachments to a subpass, when written from a previous sub pass, map exactly to on-chip tile memory in our hardware. If you’re familiar with it, this means we’re using the equivalent of EXT_shader_pixel_local_storage or EXT_shader_framebuffer_fetch for attachments.
Lazily allocated memory on our architecture starts out unallocated, as we know in advance that there’s usually no reason to allocate any memory – it exists only as an API construct, mapping only as a formatted block of registers in on-chip memory during rendering. Occasionally we may allocate a small amount of memory at framebuffer create time, or in very rare circumstances we may need to allocate the entire memory object.
Conclusion
Vulkan maps significantly better to our hardware than OpenGL ES ever has. Whilst there’s a lot of focus on Vulkan improving CPU performance and efficiency, there’s a heck of GPU performance and efficiency wins too – they’re just a bit more subtle!
Talking about console quality graphics on mobile is starting to become a bit of a cliché, but I’m going to use it anyway! As mobile GPUs get better and more efficient, Vulkan is a big step on the road to console quality graphics.
That was the last blog post in the series (a bit late but nevertheless completed!), I hope they proved useful. Remember to follow us on Twitter (@ImaginationTech) for the latest news and announcements from the PowerVR team.
In case you missed them, also check out my other blog posts and webinars on Vulkan.
Vulkan is now released, and detailed information about it is coming thick and fast. GDC is just around the corner, and you can expect a whole raft of new information there. In particular, don’t miss our developer day where we’ll be talking about Vulkan – as well as other PowerVR topics. In particular, I’ll be describing a number of techniques on how to achieve efficient rendering in Vulkan, and I’ll be participating in our ever-popular graphics panel, where we’ll discuss the impact of Vulkan on the graphics ecosystem.
Thanks for reading!
.png)


