


I’m fond of telling the story about why I joined Imagination. It goes along the lines of: despite offers to go work on graphics in much sunnier climes, I took the job working on PowerVR Graphics here in distinctly un-sunny Britain because I was really interested in how Tile-Based Deferred Rendering (TBDR) could work in practice. My graphics career to-date had been mostly focused on the conceptually simpler Immediate Mode Renderers (IMRs) of the day – mostly GeForces and Radeons.
And no offence to the folks who designed said GeForces and Radeons – a few of whom I am friends with and many more I know quite well, but the front-end architecture of a modern discrete IMR GPU isn’t the most exciting thing in the world. Designed around having plenty of dedicated bandwidth, those GPUs go about the job of painting pixels in a reasonably inefficient way, but one that’s conceptually simple and manifests itself in silicon in a similarly simple way, which makes it relatively easy for the GPU architect to design, spec and have built by the hardware team.
 Immediate Mode Rendering at work
Immediate Mode Rendering at work
With an IMR you send work to the GPU and it gets drawn straight away. There’s little connection to what else has already been drawn, or will be drawn in the future. You send triangles, you shade them. You rasterise them into pixels, you shade those. You send the rendered pixels to the screen. Triangles in, pixels out, job done! But, crucially the job is done with no context of what’s already happened, or what might happen in the future.
PowerVR GPUs are about as different as they come in that respect, and it’s that which made me take the job here, to figure out how PowerVR’s architects, hardware teams and software folks had made TBDR actually work in real products. My instinct was that TBDRs would be too complex to build so that they’d work well and actually provide a benefit. I had a chance to figure it out and five years later I’m still here, helping figure out how we’ll evolve it in the future, along with the rest of the GPU’s microarchitecture.
As far as the graphics programmer is concerned, PowerVR still looks like triangles in, pixels out, job done. But under the hood something much more exciting is happening. And while the exciting part put me in this chair so I could write about it 5 years later, crucially it’s also that other good E word: efficient!
It always starts with the classic TBDR vs. IMR debate
To help understand why, let’s keep talking about IMRs. One of the biggest things stopping a desktop-class IMR scaling down to fit the power, performance and area budgets of modern embedded application processors is bandwidth. It’s such a scarce resource, even in high-end processors – mostly because of power, area, wiring and packaging limitations, among other things – that you really need to use it as efficiently as possible.
IMRs don’t do that very well, especially when pixel shading. Remember that there are usually a great many more pixels being rendered than the vertices used to build triangles. On top of that, with an IMR pixels are often still shaded despite never being visible on the screen, and that costs large amounts of precious bandwidth and power. Here’s why.
Textures for those pixels need to be sampled, and those pixels need to be written out to memory – and often read back in and written out again! – before being drawn on the screen. While all modern IMRs have means in hardware to try and avoid some of that redundant work, say one building in the background being completely obscured by one drawn closer to you, there are things the application developer can do to effectively disable those mechanisms, such as always drawing the building in the background first.
In our architecture it doesn’t really matter how the application developer draws what’s on the screen. There are exceptions for non-opaque geometry, which the developer still needs to manage, but otherwise we’re submission order independent. That capability is something we’ve had in our hardware since before we were ever an IP company and still made our own standalone PC and console GPUs. You could draw the building in the background first, then the one in the foreground on top, and we’ll never perform pixel shading for the first one, unlike an IMR.
We effectively sort all of the opaque geometry in the GPU, regardless of how and when it was submitted by the application, to figure out the top-most triangles. Sure, if a developer perfectly sorts their geometry then an IMR can get much closer to our efficiency, but that’s not the common case by any means.
 PowerVR TBDRs
PowerVR TBDRs
Think again about all the work that’s saving, especially for modern content: for every pixel shaded there are going to be a non-trivial amount of texture lookups for various things, dozens and sometimes hundreds of ALU cycles spent to run computation on that texture data in order to apply the right effects, which often means writing the pixel out to an intermediate surface to be read back in again in a further rendering pass, and then the pixel needs to be stored in memory at the end of shading, so it can be displayed on screen.
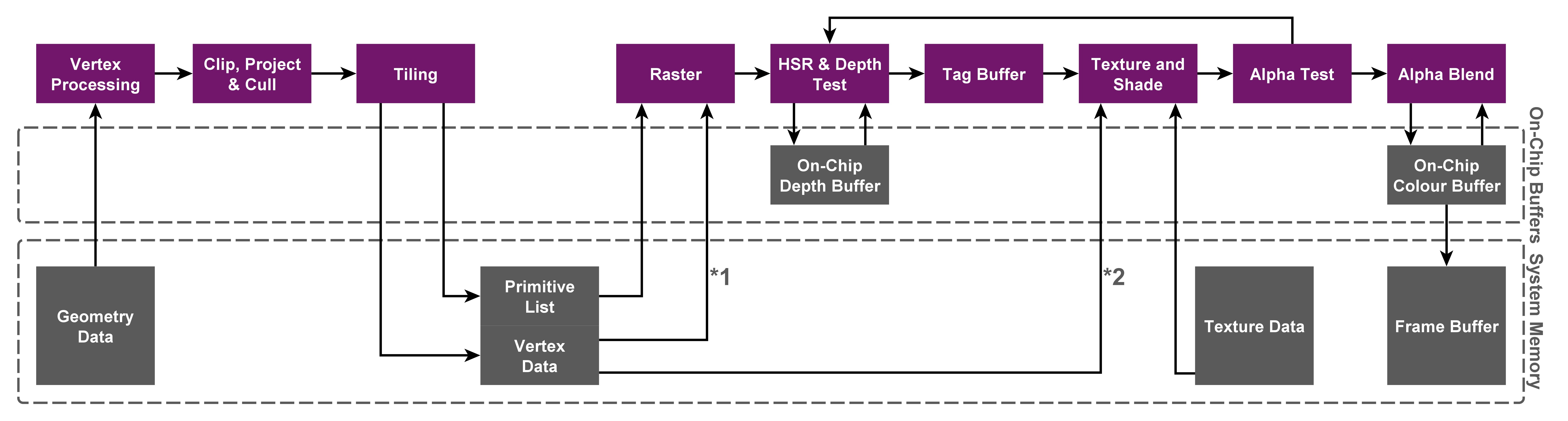
And that’s just one optimisation that we have. So even though we’ve avoided processing completely occluded geometry, there’s still bandwidth saving work we can do at the pixel processing stage. Because we split the screen up into tiles, where we figure out all of the geometry that contributes to the tile so we only process what we need to, and we know exactly how big the tile is (currently 32×32 pixels, but it’s been smaller and even non-square in prior designs), we can build enough on-chip storage to process a few of those tiles at a time, without having to use storage in external memory again until we’ve finished and want to write the final pixels out.
 PowerVR GPUs split the screen into tiles
PowerVR GPUs split the screen into tiles
There are secondary benefits to working on screen, region at a time; benefits that other GPUs take advantage of too: because it’s highly likely that a pixel on the screen will share some data with its immediate neighbours, it’s likely that when we move on to processing the neighbouring pixels that we’ve fetched the data into cache and don’t have to wait for another set of external memory accesses, saving bandwidth again. It’s a classic exploitation of spatial locality that’s present in a lot of modern 3D rendering.
So that’s the top-level view of the biggest benefits of a TBDR versus an IMR in terms of processing and (especially) bandwidth efficiency. But how does it actually work in hardware? If you’re not too hardware inclined you can stop here! If you go no further, you’ll still have understood the big top-level benefits of how we go about making best use of the available and very precious bandwidth, throughout rendering on in embedded, low-power systems.
How TBDR works in hardware
For those interested in how things happen in the hardware, let’s talk about the tiler in context of a modern Rogue GPU.
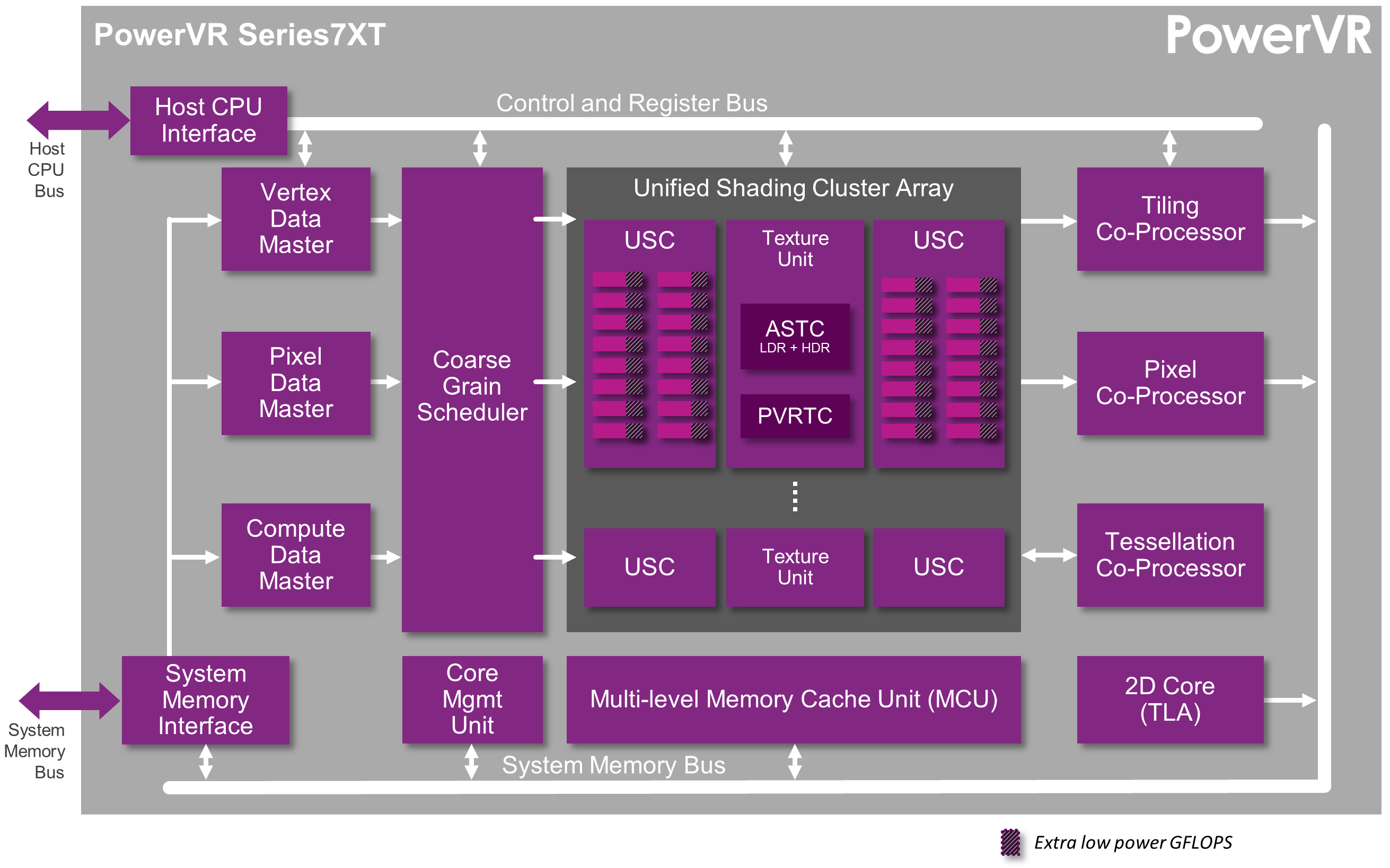
A 3D graphics application starts by telling us where its geometry is in memory, so we ask the GPU to fetch it and perform vertex shading. We have blocks in our GPUs that are responsible for the non-programmable steps of each kind of task type, called the data masters. They do a bunch of different things on behalf of the Universal Shading Cluster or USC (our shading core) to do the fixed function bits of any workload, including fetch data from memory. So because we’re vertex shading, it’s the vertex data master (VDM) that gets involved at this point, to fetch the vertex data from memory based on information provided by the driver.
 PowerVR Series7XT is the latest family of Rogue GPUs
PowerVR Series7XT is the latest family of Rogue GPUs
The data could be stored in memory as lines, triangles or points. It could be indexed or non-indexed. There are associated shader programs and accompanying data for those programs. The VDM fetches whatever’s needed, using another couple of internally-programmable blocks to help, and emits it all to the USC for vertex shading. The USC runs the shader program and the output vertices are stored on-chip.
They’re then consumed by hardware that performs primitive assembly, certain kinds of culling, and then clipping. If the geometry is back-facing or can be determined to be completely off the screen, it’s culled. All of the remaining on-screen front-facing geometry is sent to be clipped. There’s a fast path here for geometry that doesn’t intersect a clip plane, to let it make onwards progress with no extra processing bar the intersection test. If the geometry intersects with a plane, the clipper generates new geometry so that passed-on vertices are fully on-screen (even though they might be right at the edges). The clipper can do some other cool things, but they’re not too relevant for a big picture explanation like this.
Then we’re on to where a lot of the magic happens, compared to IMRs. We’re obviously aiming to run computation in multiple phases in the hardware, to maximise efficiency and occupancy: one front-end phase to figure out what’s going on with shaded geometry and bin it into tiles, then one phase to consume that binned data, rasterise it and pass it on for pixel shading and final write-out. To keep things as efficient as possible that intermediate acceleration structure between the two main phases has to be as optimal as we can make it.
Clearly it’s a bandwidth cost to create it and read it back, one which our competitors like to pick on when it comes to a competitive advantage they have over us. And it’s true; an IMR doesn’t have to deal with it. But given the bandwidth savings we have in our processing model, creating that acceleration structure – which we call the Parameter Buffer (PB) – before feeding it to our trick rasteriser, we still end up with a huge bandwidth advantage in typical rendering situations, especially complex game-like scenes.
So how do we generate the PB? The clipper outputs a stream of primitives and render target IDs into memory, grouped by render target. Think of it as a container around collections of related geometry. The relationship is critical: we don’t want to read it later and not consume a majority of the data that’s inside, since that’d be wasteful. The output at this stage is the main data structure stored in the PB. We then compress the memory, and in the general case it always compresses very well, so we save quite a lot of PB creation bandwidth just from that step alone.
The concept of tiling
Now for the bit that most people sort of understand about our hardware architecture: tiling. The tiling engine has one main job: output some data that marks out a tiled region, some associated state, and a set of pointers to the geometry that contributes to that region. We also store masks just in case a primitive doesn’t actually contribute to the region, but is stored in memory anyway. That lets us save some bandwidth and processing for that geometry, because it doesn’t contribute to the tile.
We call the resulting data structure a primitive list. If you’ve ever consumed any of our developer documentation, you’ll have seen mention of primitive lists as the intermediate data structure between the front-end phase and the pixel processing phase. Next, some more magic that’s specific to the PowerVR way of doing things.
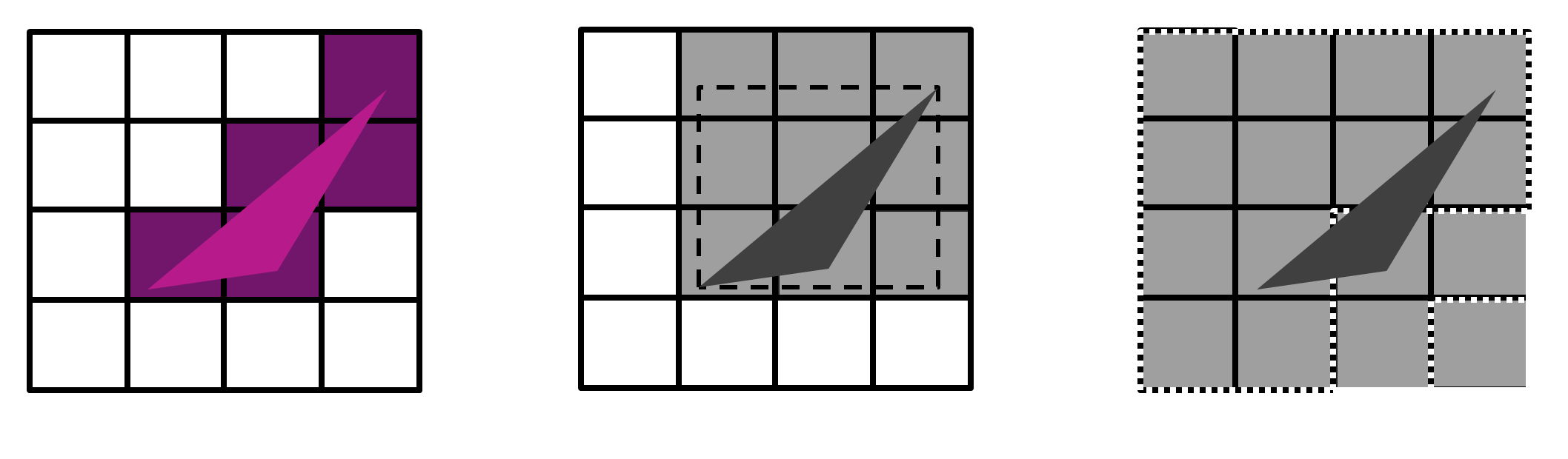
Imagine you were tasked with building this bit of the architecture yourself, where you had to determine what regions need to be rasterised for a given set of geometries. There’s one obvious algorithm you could choose: the bounding box. Draw a box around the triangle that covers its extents, and whatever tiles that box touches are the ones you rasterise for that triangle. That falls down pretty quickly though, efficiency wise.
Imagine a fairly long and thin triangle drawn across the screen in any orientation. You can quickly picture that the bounding box for that triangle is going to lie over tiles that the triangle doesn’t actually touch. So when you rasterise, you’re going to generate work for your shading core, but where nothing is actually going to happen in terms of a contribution to the screen.
Instead, we have an algorithm baked into the hardware which we call perfect tiling. It works as you’d expect: we only generate tile lists where the geometry actually covers some area in the tile. It’s one of the most optimised and most efficient parts of the design. The perfect tiling engine generates that perfect list of tiles for a given set of geometry.
 PowerVR perfect tiling vs. bounding box or hierarchical tiling
PowerVR perfect tiling vs. bounding box or hierarchical tiling
That tile information plus the primitive lists are packed into the PB as efficiently as we can, and that’s conceptually pretty much it. In reality there’s a heck of a lot that still happens here in the hardware at the back-end phase of tiling, to fill the PB and organise and marshal the actual memory accesses for the external memory writes, but in terms of functionality to wrap your head around, we’re pretty much done.
That front-end hardware architecture for us is really where a really big chuck of the efficiency gains can be found in a modern PowerVR GPU, compared to some of our competition. Surprisingly to those who find out, it’s part of the hardware architecture that’s not actually that different, at least at the top-level, between Rogue and SGX. While we completely redesigned the shader core for Rogue, the front-end architecture actually bears a strong resemblance to the one you’ll find in the later generation SGX GPU IPs. It works and it works very well.
And now that I’m done explaining the tiling part of our TBDR, it’s a good excuse to stop! I’ll come back to the deferred rendering part in a future blog post, so stay tuned.
.png)


