


As discussed in my previous blog posts and articles, Imagination’s engineering force is dedicated to efficiency. The PowerVR ‘Rogue’ architecture is our first architecture designed for compute. Of course, efficiency and common sense were liberally applied to the design process of this functionality. This approach helps us to deliver solutions that match true market requirements, while keeping in mind that efficiency and power consumption are the two most critical factors to consider as we design our PowerVR mobile GPU family.
Balancing features with performance and power
Blindly implementing every possible feature is a simplistic approach to hardware design, as it is all too easy to forget about the cost impact (e.g. silicon area) or, even more importantly for mobile designs, power consumption. Hence it is critical to find the right balance between feature set – linked to industry standard APIs (more on this later) – and power consumption. The same is true for performance. Designing a GPU with stellar performance but little care about cost or power consumption leads to a product that fails to match essential market requirements.
In our GPU IP design flow, every effort is made to provide the best balance, investing where required, but holding back where a feature is likely to go unused (which would end up as an area and power consumption cost).
As our architects looked at the existing GPU compute APIs for the workstation PC market, several features jumped out as poor matches for mobile battery-driven systems. This insight was fed back into compute API design efforts, resulting in the creation of optimal profiles for mobile systems. A good example of such an optimised feature set is the OpenCL Embedded Profile (EP) API from the Khronos Group. These mobile optimised API variants skip niche features which are only of use for a very small set of usage scenarios (if any) or which are only applicable to non-mobile usage scenarios such as scientific and academic compute (as discussed before, mobile compute must be practical compute).
Here are just a couple of examples to illustrate this and the link to the ever critical power consumption:
First questionable feature: 64-bit floating point (FP64) support. The most common floating point representation is 32-bit wide (FP32) and is known as single precision. For more extreme usage scenarios which require very large precise numbers, a double precision 64-bit format exists. It should come as no surprise that moving from 32-bit to 64-bit arithmetic units is not something which is free in terms of silicon area or power consumption. As a result, this raises red flags in terms of a mobile focussed GPU design – do we really need 64 bits? In the case of FP64, the answer is actually simple.
FP64 is an optional feature in every compute API, even those for high-end, power-guzzling PC systems. As a result, adding dedicated hardware to enable FP64 in a mobile design is clearly a flawed decision. After all, why add something to a power-sensitive product when it is even optional for desktop products?
A second questionable feature: precise rounding mode support. Rounding modes control the behaviour of the last bit of precision in your number representation. It’s a bit like rounding fractional numbers to the nearest integer number. If we have 12.75 as an example value, and our numerical representation does not support fractions, do we round this to 12.7 or to 12.80? And an additional question: do we even need to worry about the rounding to 12.7 or 12.8? Obviously this question depends very much on the usage scenario – for example if we are looking at money 12.7 or 12.8 million versus 12.7 or 12.8 cents makes a big difference.
Hence this is where power consumption impact and practicality of the algorithms come into play. Rounding is not as trivial as it may sound. Adding more complexity costs more in terms of silicon area and is also linked to higher power consumption.
Additionally, if we already have a large number of representative numbers, does that last bit of fractional rounding really matter? For example, if a colour channel gets the colour 232 or 233, can we even really tell? Looking at numerous desktop compute applications with a link to practical usage scenarios for mobile devices, our teams found that rounding makes little or no difference to the practical results of algorithms. A more practical indication: image/video processing typically bring in 8 bits of colour data per channel, this data must be processed to generate another 8 bits output image. Doing this processing using 32 bits floating point offers far more precision than the input or output data needs, obviously this means that investing in accuracy of the rounding precision is a waste of silicon area and, worse, a waste of valued power budget.
While small differences are possible due to rounding, we generally find that numerical accuracy in operations always carries variable errors anyway. We actually found this out the hard way, as we were running through compute API conformance tests on different systems. Our GPU passed conformance on an Intel x86-based system, but when running on an ARM-based system, that same GPU failed conformance. Odd or not?
Actually not odd at all, as the reason is small differences in numerical precision between the Intel x86 implementation and the ARM implementation. So if two of the leading CPU architectures cannot even return the same reference values, why do we need to bother about the last bit of rounding precision in general? In most situations, depending on the last grain of precision puts you in an unstable area of the algorithm, as you need every last bit of precision to generate the correct result. This borderline type of calculation leads to instability, and is what often can be seen as flickering and jittering in images or animations. It is something you want to stay away from, and not depend on. Given all of the above, it’s clear that on the rounding mode subject, going for lower power is clearly the better choice for mobile GPUs.
Just to clarify even further, from a design point of view, GPUs have tens if not hundreds of compute engines (ALUs). Anything you add to these units in terms of functionality makes them more complex. This translates to extra silicon area and extra power consumption, which gets multiplied by the number of engines in the overall GPU. Adding FP64 support, adding more advanced rounding modes, adding exception handling, adding multi-precision, etc. – every bit of complexity you add ends up costing you. ALU design is definitely an area where “keep it clean and simple” (or “lean and mean”) applies in terms of silicon area, and also, critically, applies in terms of power consumption.
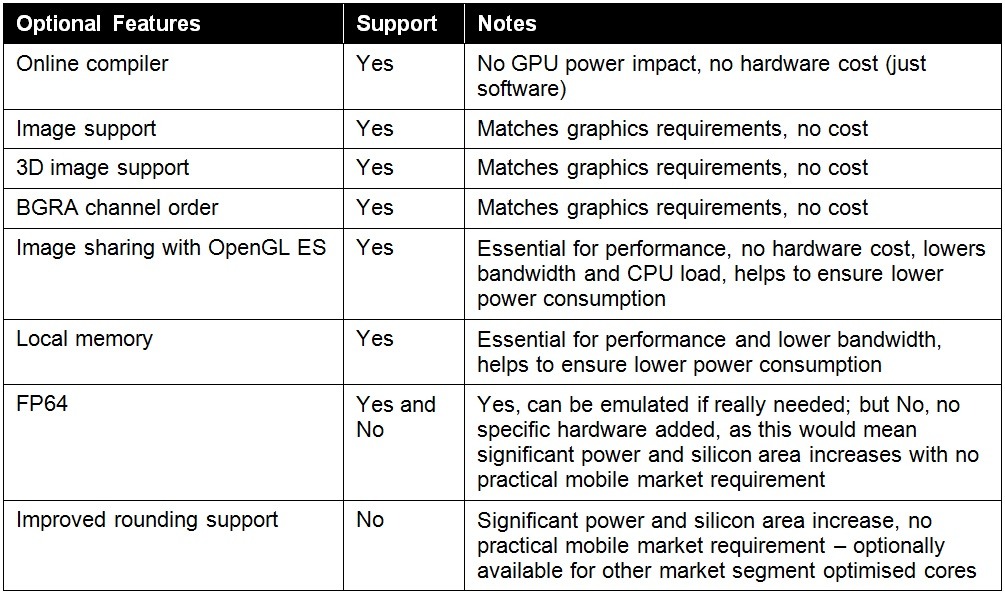
Looking across the overall feature set of compute APIs, there are however numerous other features which can be implemented with minimal or no silicon area and/or increase in power consumption. Many of these are still optional in mobile compute APIs, but for ease of porting and application compatibility, these optional features should be supported – especially as some can actually lead to reduced power consumption. This is illustrated in the table below:
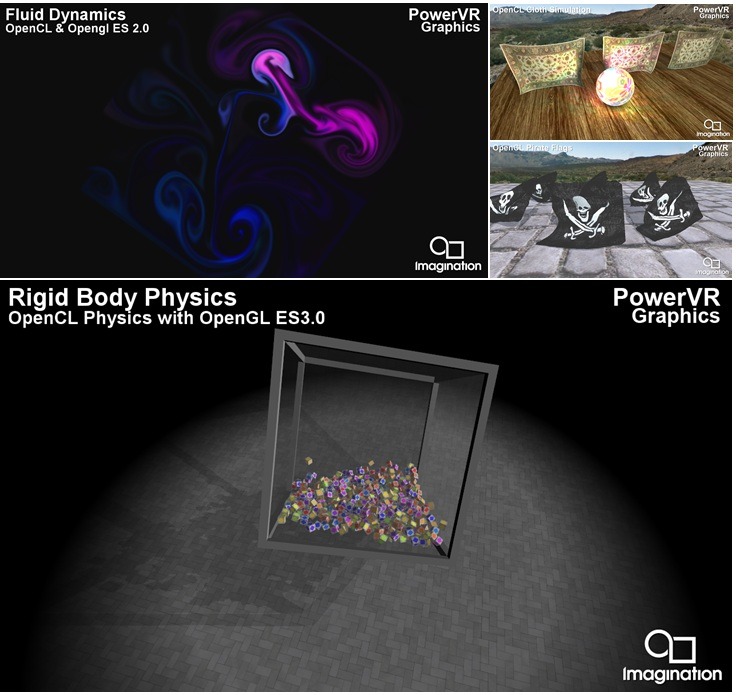
Through our extensive ecosystem, as well as an early access program, Imagination’s feature set choices are being confirmed as the right choices. Even in third party benchmark applications, claimed to be desktop profile, we note that all of the effects implemented do not actually depend on niche desktop features nor on extreme precision, as all tests execute and run well on multiple embedded profile implementations. Internal tests also confirm this; we have developed several practical usage scenarios for mobile, focussing on image processing. We’ve also confirmed on alternative usage scenarios (checking compatibility with our power streamlined feature set), such as fluid dynamics calculations, cloth and rigid body physics calculations, and even video decoders. None of these have proven to have any requirement for desktop profile feature sets as shown below:
.png)


