

We’re halfway through our series of blog posts on Vulkan – hopefully you’ve checked out the other blog posts, or tuned into the webinars, and are following so far!
This post I’ll be discussing the importance of scaling to multiple threads, and how Vulkan helps achieve that.
CPU bottlenecks – redux
Modern CPUs have multiple cores, for a variety of great reasons which I won’t discuss here. In order to get the best performance out of a particular CPU, it’s important to be able to make good use of these additional cores by using multiple threads. If you don’t make use of these cores, you’ll be limited to to the performance of a single core – which leaves a lot of performance (and efficiency) on the floor. Previously, I wrote about the GPU waiting on the CPU as a function of an inefficient API with a high CPU overhead. Even with a high overhead, the problem could be somewhat mitigated by spreading the workload across multiple threads.
If you look at the CPU graphs in our Gnome Horde demo, you can see that OpenGL ES spikes a lot higher for the same content. It’s continually maxing out either core 0 or core 1, and suffering a performance penalty as a result. Yet there are four Intel CPU cores available on the Nexus player; and two of them appear to be just sat idle. In fact there’s really three idle at any given time! The only reason you see two apparently active is because the OS is bouncing the thread between cores in an attempt to keep the chip cool.
So not only is OpenGL ES doing too much work, it’s also not able to distribute that work to processors that could otherwise help. Older APIs like OpenGL ES do not scale to multiple software threads very well at all – about the most you can manage is to do resource streaming on another thread, with quickly diminishing returns if you try to do anything else. Many high-performance applications or engines resort to making sure they do the bare minimum on a rendering thread, with all the logic handled as much as possible on other threads – often generating their own form of command buffers.
Use all the cores
If you could distribute the rendering thread’s workload across multiple cores, you’d see much better CPU performance. From about 15 seconds into the video, the Gnome Horde demo starts generating and destroying a lot of gnomes per frame – on the order of 150k new draw calls per second, plus 250k re-used ones. In OpenGL ES there’s not much we can do about that; the single core it’s using is already maxed out. Vulkan, however, can seamlessly makes use of all the available cores by redistributing this workload across a number of threads.
It’s also important that the work actually scales without just generating more work. In order to be truly scalable, an API needs to be able to spread its workload across multiple threads with as close to zero additional overhead as possible. Unsurprisingly, Vulkan provides mechanisms to do just that – which you can again see in the Gnome Horde demo.
 Vulkan CPU vs OpenGL ES CPU: Note how OpenGL ES cannot do multi-threading
Vulkan CPU vs OpenGL ES CPU: Note how OpenGL ES cannot do multi-threading
Vulkan mechanisms for scaling
Vulkan doesn’t just magically scale to multiple cores behind your back – this is an explicit API after all. However what it does do is provides the tools and mechanisms needed in order to allow applications to scale as they want. Some of this is achieved just by some simple design choices, and yet more by providing objects that explicitly cater to multi-threading.
No Global State
OpenGL ES has the idea of contexts bound to CPU threads, which isn’t quite “global state” in the true sense, but global enough to cause issues with threading. In most cases, when you call a function, the driver has to lookup the context, which is tied to the current thread. This is usually doing using some form of Thread Local Storage, which isn’t particularly great for performance, particularly when doing it for almost every function! With OpenGL ES’s bind-to-edit model, most functions require further lookups within that context in order to obtain the currently bound object, causing yet more issues.
Vulkan has no global state, or at least no mutable global state – there’s fundamentally only a certain number of GPUs on your system, and short of doing something beyond an application’s control, that’ll stay constant for the lifetime of an application. Vulkan is very explicit in that every object provided to each function (rather than via a bind call); and any time the dispatchable object (e.g. the device) that owns it is involved, it is provided as an argument to that function. This means no global lookups, or locks on global state.
External Synchronization
OpenGL ES has the property that modifying anything at any time is completely thread safe, as far as the CPU is concerned. That sounds nice in principle, but it means that whether you’re application is multi-threaded or not, the driver is jumping through hoops to avoid race conditions. In practice this often means mutex locks around any functions that cause modifications – which is one of the more subtle causes of high overhead in OpenGL ES. The driver has little to no knowledge of how an application is going to access state, at least without invoking careful heuristics – so it becomes difficult to do anything but be very conservative and lock down everything.
Vulkan on the other hand only guarantees concurrent read access to objects and state. If any thread modifies an object, the application must ensure that no other access to that object happens concurrently. Via careful API design choices, it’s usually completely unnecessary to modify the same object from multiple threads at any given time. If an application really needs to modify the same object on multiple threads, it must use its own synchronization mechanisms to avoid race conditions and data hazards.
By throwing the synchronization problem at developers, it means that applications have the opportunity to do better than the driver. In most cases, synchronization between threads can be done at set communication points, potentially without the need for a mutex; preventing a lot of potential idle time!
Multi-Threaded Command Generation
OpenGL ES makes no distinction between command generation and command submission. When you call “glDraw”, it both translates all the current state into something for the hardware to consume, and also submits that for execution. Actually generating the commands is quite an expensive operation (made worse by OpenGL ES’s inefficiencies), and since you generally need to serialize all the submissions, you have to do all your command generation on one thread at a time.
In Vulkan, the concept of generation and submission are entirely separated, with commands being first recorded into command buffer objects, and then later submitted to hardware queues. This allows applications to record command buffers on other threads, and in fact on multiple threads as well, with the submission being a relatively cheap CPU operation that can be done on any single thread with negligible impact.
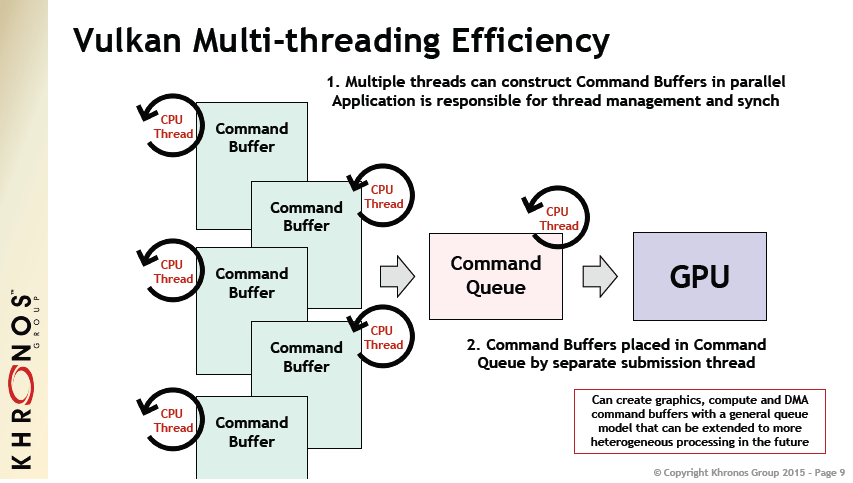
This allows for much more efficient divisions of work, with recording designed to scale well across multiple threads without incurring much additional processing costs.
There is a cost to recording commands could be have been difficult to scale well – command buffers need memory to record into, and it’s not practically possible to know how much memory is required in advance. Allocating memory at the base level is a global operation – requiring a lock of some kind, and blocking other threads. In order to alleviate this, command buffers employ a few different strategies to avoid having to go to the system for memory:
- Command buffers can be reset, which allows them to be re-recorded without freeing any memory they’ve allocated. If the allocation size in a single command buffer remains stable, there’s no need to allocate memory from the system every frame, only the first frame pays the costs.
- Command pools allow a group of command buffers to share a larger allocation, so that if the workload per-command buffer varies frame to frame, but the per-pool workload doesn’t really change, this provides a way to maintain some level of stability without every command buffer enormously over-allocating.
For more information on command buffers and command pools, I point you to Jesse Barker’s portion of the SIGGRAPH BoF, where he discusses changes to Vulkan, including these objects. There’s subtle detail in how these constructs operate and how they should be used to actually achieve proper multithreaded scalability, and I’ll be able to talk more about this in future.
Conclusion
As with my last blog post, this is only really scratching the surface – I’m highlighting some big ticket features that allow threading, but these strategies permeate through the entire API. Vulkan should allow much better scalability than OpenGL ES, and even if you don’t end up using multiple threads, at least the option is there for those who do!
What this means practically for developers, is that on device with more cores you’ll simply be able to manage your threads better, and allowing rendering strategies that weren’t previously possible. As I alluded to last time, this will lead to better efficiency and better performance of applications that otherwise find themselves maxing out a single core!
Remember to follow us on Twitter (@ImaginationTech) for the latest news and announcements from the PowerVR team.
In case you missed it, also check out my last blog post High efficiency on mobile.
.png)


