

It was clear last week at the annual Embedded Vision Summit in Santa Clara that the time of computer vision and deep learning on mobile had finally arrived. Interest in the area is growing noticeably – the Summit program expanded from one to two days this year, there were an impressive number of attendees, and the Technology Showcase was busy throughout the show.
The overall industry sentiment seems to be that while vision is still quite a difficult challenge, it is becoming a more and more a solvable problem. There is active development for vision processing applications in multiple different market segments including automotive, surveillance, photography and consumer electronics.
One of the interesting points made during the show was in a presentation by Cadence Design Systems that showed the incredible growth in the number of sensors – whether they be cameras, gyroscopes, thermometers, proximity sensors etc. – in today’s devices. When you look at the amount of data generated by these sensors, suddenly the chart is dominated entirely by the massive amount of pixels generated by cameras/vision sensors.
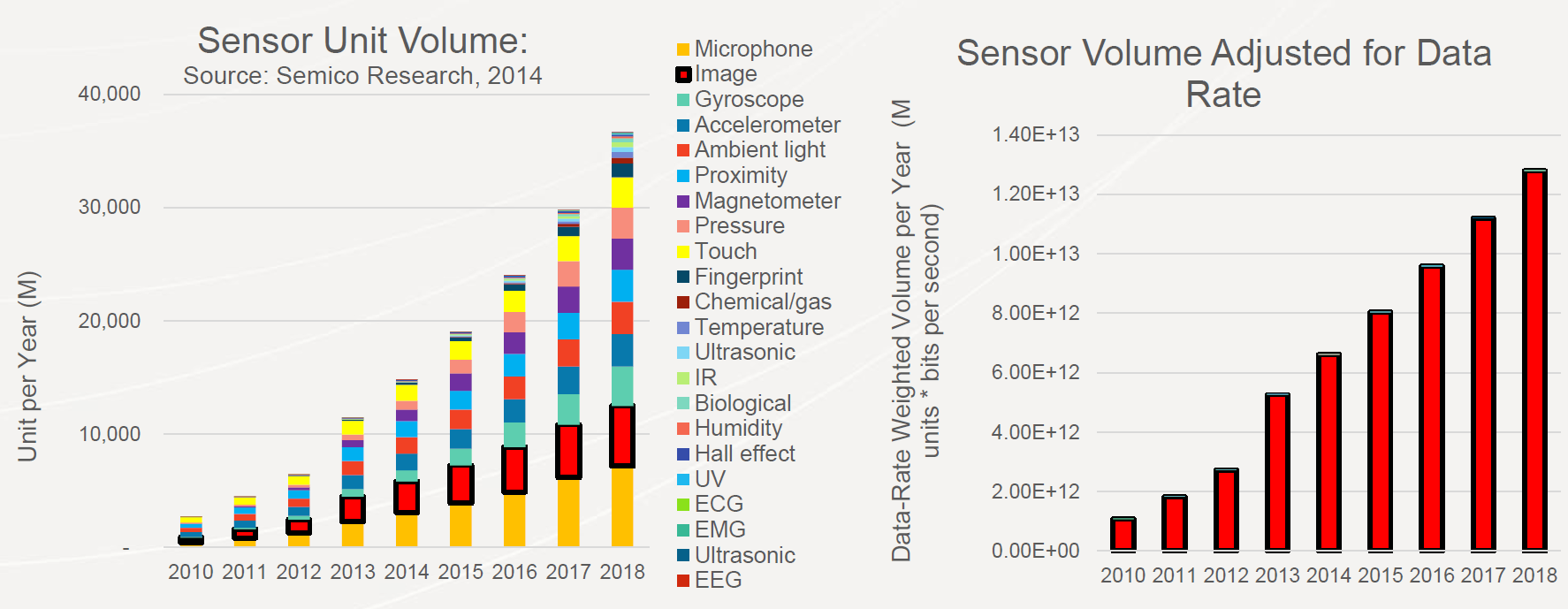 Cadence highlighted the massive amount of data generated by images
Cadence highlighted the massive amount of data generated by images
Visual information is the highest bandwidth, most information-rich way in which consumers interact with the world. The challenge is in analyzing and using that visual data – since it has the potential to absorb almost unlimited computing resources and huge amounts of bandwidth. The processing of this data will increasingly require optimised solutions from sensor to output, to minimise the power and bandwidth, whilst giving the required performance – and I’m very excited to see our latest PowerVR multimedia IP developments developments specifically targeting these applications.
Jeff Dean from the Google Brain team pointed out that with neural networks, results get better with more data, bigger models, and more computation. He described the deep learning work being done by the Google Brain project since 2011, with unique project directories now numbering ~1,200, and being used for Android apps, drug discovery, Gmail, image understanding, maps, natural language, understanding, photos, robotics research, speech, translation, YouTube and more. With all of the work going on, results are definitely getting better. See the chart below – the latest GoogLeNet Inception architecture now scores better on image recognition than humans!
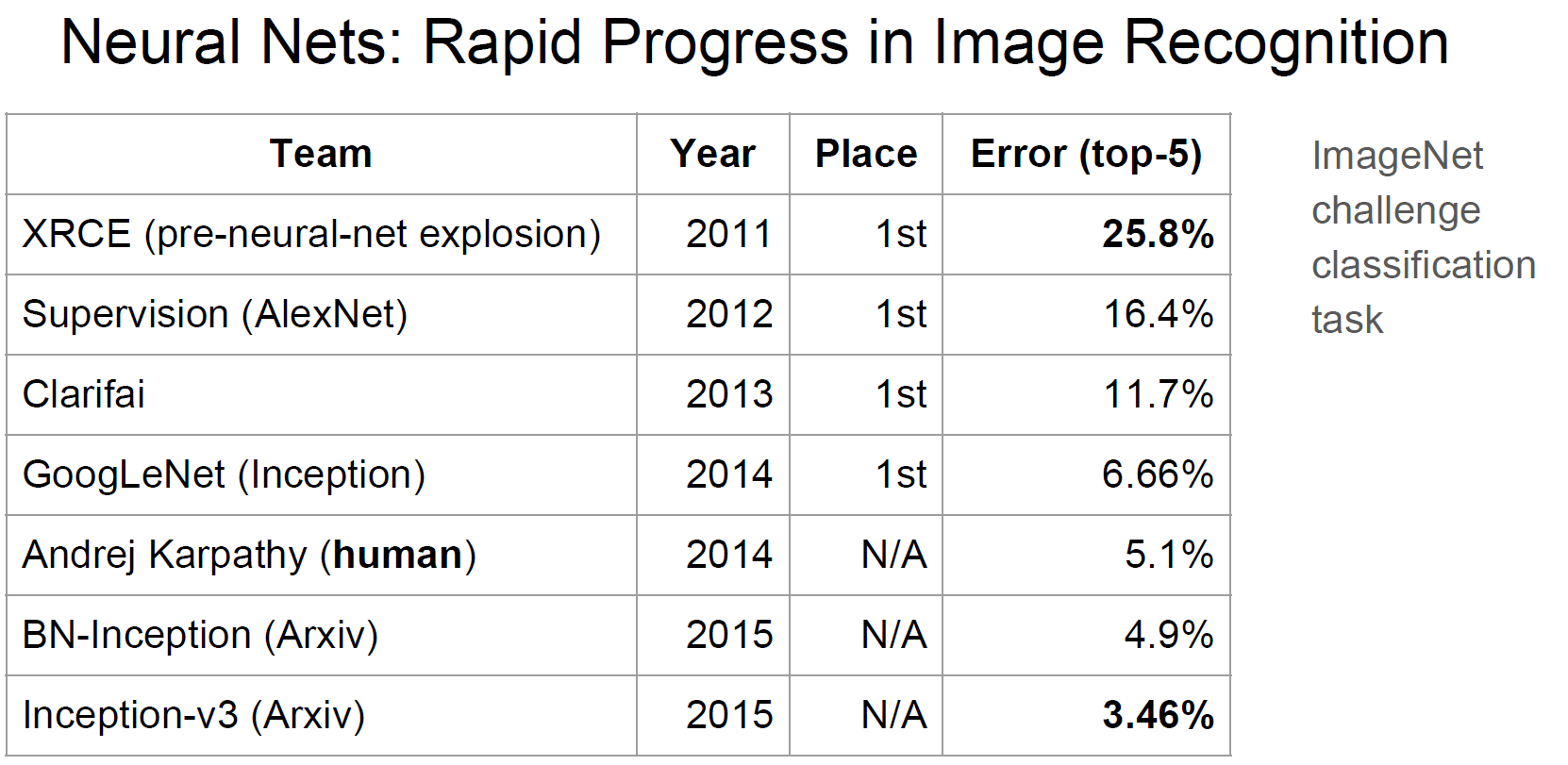 Google presented the rapid progress in image recognition in neural nets
Google presented the rapid progress in image recognition in neural nets
From a technology perspective, one of the biggest focuses at this year’s show was around convolutional neural networks (CNNs). For those of you not submerged in the world of vision processing, CNNs are a form of machine learning that model the manner in which the brain’s visual cortex identifies and distinguishes objects.
Using Deep Learning algorithms, CNNs can be used for computational photography, computer vision, AR/VR, etc. Google are one of the leaders in this field, and their open-sourcing of the Tensor flow engine aims to further the development of models, software and hardware by multiple players in the industry. Beyond the Google tools, others are also available to take advantage of these rapid developments in deep learning, with other frameworks such as Caffe also freely available.
At the Summit, my colleague Paul Brasnett presented Efficient Convolutional Neural Network Inference on Mobile GPUs. Paul talked about how it’s possible today to run state of the art CNN algorithms on the millions of PowerVR mobile GPUs that are already available in a range of SoCs across numerous markets. For things like computational photography, augmented reality, object recognition and more, the performance is quite remarkable. Compared to mobile CPUs, PowerVR GPUs offer up to 3x higher efficiency and up to 12x higher performance deployment for CNNs. Newer CNN architectures with smaller fully connected layers help to make more efficient use of compute resources. During the Technology Showcase, we demonstrated this concept – see below.
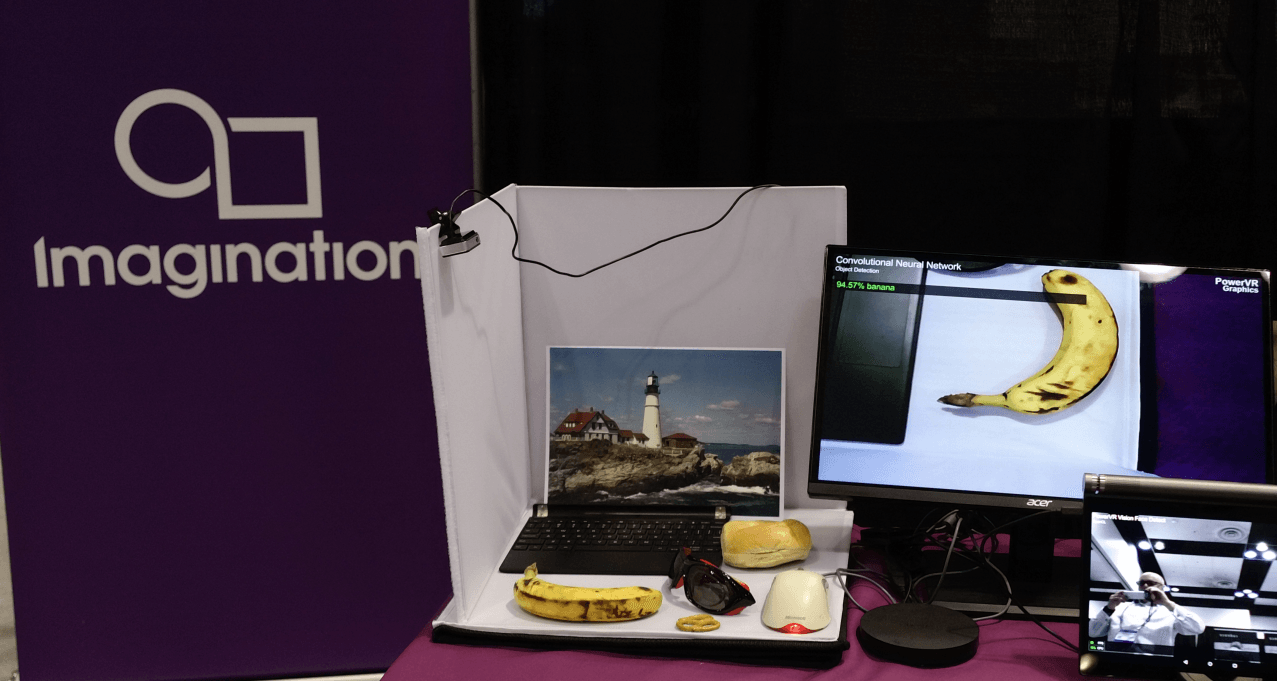 Imagination demonstrating CNNs running on a PowerVR Rogue GPU
Imagination demonstrating CNNs running on a PowerVR Rogue GPU
Our demo used a Google Nexus Player with a Intel Atom quad-core SoC, containing a PowerVR G6430 GPU. The application runs on the Caffe framework alongside Alexnet accelerated using OpenCL. The demo uses the live input from the camera to identify the objects the camera is pointing at, along with an indication of the confidence level produced by the network. The performance is several times higher than a CPU running the same network.
Embedded vision is exploding across a wide range of applications, from computational photography and gaming to AR/VR and robotics, to smart cars and drones, and far, far beyond. With the huge leaps being made in this area, it will be amazing to see where we are as an industry at next year’s Summit.
Make sure you also follow us on Twitter (@ImaginationTech) for more news and announcements from Imagination.
Do you think that CNN’s will be the dominant method used for vision processing in your application area?



