


The versatility and power of deep learning means that modern neural networks have found myriad applications in areas as diverse as machine translation, action recognition, task planning, sentiment analysis and image processing. This is inevitable as the field matures, and there is a high and growing degree of specialisation, which is an accelerating trend. This makes it a challenge to keep with the current state of the art, let alone predict the future compute needs of neural networks.
Designers of neural network accelerator (NNA) IP have a Herculean task on their hands: making sure that their product is sufficiently general to apply to a very wide range of current and future applications, whilst guaranteeing high performance. In the mobile, automotive, data centre and embedded spaces targeted by Imagination’s cutting-edge IMG Series4 NNAs, there are even more stringent constraints on bandwidth, area and power consumption. The engineers at Imagination have found innovative ways to address these daunting challenges and deliver ultra-high-performance and future-proof IP.
Utilisation vs. Flexibility
At the heart of every IMG Series4 multi-core NNA is an industry-leading convolution engine array capable of executing 10 trillion operations per second. A four-core Series4 is capable of an eye-watering 40 trillion ops per second, or 40 TOPS for short. One distinguishing feature of its architecture is its efficiency; data is packed together as tightly as possible on the inputs to the convolution engines to achieve the greatest possible utilisation, meaning that chip area is kept to a minimum. The Series4 contains several such highly optimised, blisteringly fast configurable hardware modules, for operations such as pooling, normalisation and activation functions.

This degree of specialisation obviously pays huge dividends where the network is a good match for the hardware – that is when it is composed of “conventional” layers such as convolutions, pooling and activations – but how can such an architecture be extended to support more complex operations such as attention mechanisms and non-maximum suppression?
There are two apparent options available:
- Add new specialised blocks to the hardware.
- Make the hardware highly programmable and general purpose.
The main problem with the first of these is that it leads to hardware bloat and dark silicon – do we want a fixed-function module if it’s only active for, say, 1% of the compute time in a few applications? No – we must get the best possible hardware reuse. It would also mean that the hardware is always playing catch-up with the state of the art. Adding fixed-function modules would mean that the hardware is not “future-proof”, limiting its applicability to those operation types already encountered by the NNA’s designers. The first approach leads to hardware bloat or forces the use of additional “co-processors”, such as GPUs, DSPs or CPUs; silicon area, bandwidth, energy and complexity all increase.
Most players in the business of NNA design go for the second option. Examples of this kind of approach are vector ALU and systolic array-based designs. Complexity is shifted away from the hardware and into the software, which is all in keeping with the time-honoured RISC (Reduced Instruction Set Computer) philosophy of computer architecture. There is, however, a big price to be paid – a decrease in computational density. To reach their target of 40 TOPS, the Series4 architects would have had to tolerate a substantial increase in chip area and power consumption.
Researchers at Imagination decided that there must be a third way. Their strategy is to trade utilisation for flexibility using novel compilation techniques and a new design philosophy that they call Reduced Operation Set Computing (ROSC). Series4 has enormous computational density for running standard layers such as convolution, pooling, activations and fully connected layers that account for most of the computational requirements in most neural networks. Essentially, it has computational capacity to spare.
Simply put, ROSC is about reconfiguring and recombining operations from this reduced operation set to build a very wide variety of other operations: operations that might, at first sight, appear difficult to implement in terms of these base operations. This re-tasking generally results in lower utilisation since the hardware modules are not being used for their primary purposes; however, since Series4 has so much raw compute power, even at 1% utilisation for example (400 giga-operations per second) it is often still far faster to run a complex operation on it than to execute it “off-chip”, for example on CPU or GPU. Keeping processing on-device in this way saves precious system resources including CPU/GPU time, power and bandwidth.
Complex operations may be implemented as a computational graph of simpler operations that require multiple hardware passes. For this reason, Series4 uses a novel on-chip memory system with tensor tiling to keep data local [see link for a detailed white paper on this subject] – this can be exploited to run complex operations over multiple hardware passes with minimal system overhead.
The key insight underlying the ROSC concept is that specialised hardware modules can often be configured to do other tasks. Even when utilisation drops because of this re-tasking, it is more than made up for by the massive computational capability of the hardware. This allows the Series4 architects to have their cake and eat it – for no additional hardware complexity, or area, Series4 can be both lightning-fast where raw performance matters and flexible enough, when necessary, to handle arbitrarily complex high-level operations.
Don’t Underestimate the Architecture!
Series4 has five main configurable types of computational hardware module, which can be referred to as:
- Convolution Engine
- Pooling Unit
- Normalisation Unit
- Elementwise Ops Unit
- Activation Unit
Each of these configurable hardware modules can do more than might seem possible at first glance. For example, Series4 convolution engines can be configured to carry out the operations shown in Figure 1 (and many others besides) without recourse to the other computational hardware modules. An even wider range of operations can be implemented using a combination of several such modules. In fact, it turns out that Series4 can be configured using advanced graph lowering compiler techniques to cover almost all operations encountered in modern neural networks.
Labels can be misleading. Simply because a hardware module is labelled “convolution engine” or “pooling module” does not mean that that is all it can do – in the right hands, these modules can do far more than they say on the tin! Two examples of implementing complicated operations using combinations of multiple hardware modules are given below.
Softmax
Softmax is a common operation in neural networks, often used where a discrete probability is needed. It is also used in some cases to normalise a tensor so that all elements along a certain axis or axes are in the range [0,1] and sum to 1. Softmax typically counts for a small fraction of compute in a network. For example, in most ImageNet classification networks, softmax accounts for less than 0.01% of compute. In keeping with the ROSC strategy of avoiding wasting chip area as “dark silicon”, Series4 has no dedicated softmax hardware; instead, it is implemented in terms of other available operations. This makes it a prime example of how we can apply the principles described above. Essentially, the strategy is to replace the softmax with a series of operations (a “computational subgraph”) that is mathematically identical but is made from operations that are directly supported in the hardware.
Softmax is a complicated operation requiring five stages, as shown in Figure 2. Four of these – the cross-channel max reduction, exponential, cross-channel sum reduction and division – have no dedicated hardware on Series4 either! There are, however, inventive ways in which we can run these on Series4, as described below.
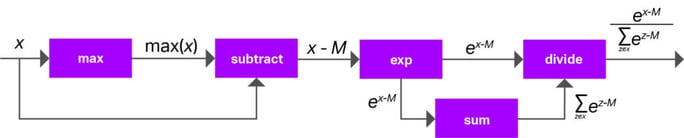
- A 1×1 convolution with a weight tensor with a single filter composed entirely of ones can be used to implement the cross-channel sum.
- Division can be implemented as a multiplication of one tensor with the reciprocal of the other. Series4’s LRN (Local Response Normalization) module can be configured to compute a reciprocal.
- Cross-channel max can be done by transposing the channels onto a spatial axis and doing a series of spatial max-pooling ops. Afterwards, it is transposed back onto the channel axis.
- Since the exponential is limited to negative and zero input values, the activation LUT can be configured with an exponential decay function.
In all, this results in a replacement subgraph containing around 10 to 15 operations (depending on the size of the input tensor), performed over several hardware passes. The insight of ROSC is that this graph is faster and much simpler to execute than the alternative of executing on a CPU or co-processor. Both extremes of fully programmable and dedicated fixed-function hardware are avoided, and complexity is contained in the compilation process where it is most easily managed.
What is more, the operation replacements used for softmax can be reused for other high-level operations. Once a few such high-level operations have been implemented, it is easy to see how a library of reusable operation replacements can be built up, making future operations easier to lower onto Series4. This is how ROSC leads to futureproofing.
3D Convolution
The convolution engines and associated data input and output in Series4 are very highly optimised for 1D and 2D convolution – this makes a lot of sense because these account for the vast majority of compute in most CNNs (convolutional neural networks).
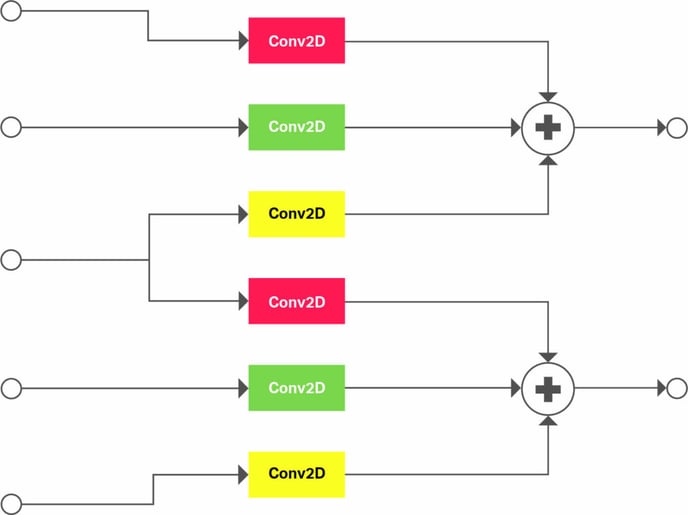
However, 3D and higher-dimensional convolutions are not supported natively in the Series4 hardware. 3D convolution is a specific example of a complex operation that can be lowered onto Series4 using graph lowering techniques. In this case, the subgraph is built from 2D convolutions and elementwise additions. Wherever the compiler “sees” a 3D convolution in the original graph, it will replace it with an equivalent version of this subgraph before generating the machine code to run on Series4.
Figure 3 shows an example of a 3D convolution with a kernel size of 3 and stride of 2 on the depth axis. The convolution is unrolled on the depth axis. Convolutions with the same colour share the same weights. This strategy is easily extended to higher dimensions and other 3D operations, such as 3D pooling and 3D deconvolution. This approach to 3D convolution is a good example of how the software can be designed to work with the strengths of the hardware, extending its applicability.
Conclusion
High-performance neural network accelerators are difficult to design because they need to balance two seemingly contradictory goals: they need the massive parallelism and computational density to crunch through the millions of operations in a typical neural network in a fraction of a second; and they need to be sufficiently flexible to handle the hundreds of diverse types of operation in modern neural networks, as well as those which have yet to be invented! A compromise has usually to be made between a highly efficient, more fixed-function approach and a less efficient but more general-purpose approach.
Engineers at Imagination have developed an exciting innovative approach that offers the best of both worlds. Series4 does not contain anything approximating the ALU that is required for programmability – it instead has several very efficient hardware modules designed to perform computation for specific, commonly-occurring operations. Full flexibility is achieved using novel compilation techniques, by which a very wide range of operations can be built out of a reduced set of basic operations. This approach is described by the new moniker Reduced Operation Set Computing (or ROSC for short). By coordinating hardware and software design in this fashion, Series4 boasts future-proof, world-beating performance and computational density without sacrificing flexibility.



