


Last year I read a fascinating article on LinkedIn about using deep-learning-based super-resolution networks to increase the apparent detail contained in images and videos sent back by Nasa’s Perseverance Rover. This article got me thinking about how, when I first watched Blade Runner in the 90s, scenes such as “enhance 15 to 23” seemed so implausible based on the technology available at that time. At that point (and because of films like Blade Runner) I was embarking on a three-year degree course in artificial intelligence and I could not have predicted the impact of the deep learning revolution at the start of the millennium. You can’t add what isn’t there, I kept saying to myself. But now, it seems, you can – and it’s extremely convincing.
How can super-resolution be applied in the real world?
Applications for super-resolution are far-reaching; from the nostalgic restoration and colourisation of old photographs to reducing video streaming bandwidth by up-sampling low-resolution source content. As the author of the “Upscaling Mars” post explains, upgrading cameras on a planetary exploration vehicle is not feasible, so if greater detail through increased resolution is desired, or even in the catastrophic scenario where an onboard lens becomes obscured or damaged, state-of-the-art super-resolution techniques can provide great value. There have also been many examples of archived or historical images and videos being revitalised with an increase of resolution, or, where the original image was black and white, through colourisation.
What is deep-learning-based super-resolution?
Deep-learning-based super-resolution is the process of applying learned up-sampling functions to an image with the intention of either enhancing existing pixel data within the image or generating plausible new pixel data (thus increasing the resolution of the image). The colourisation example mentioned above gives some insight into how deep learning methods make use of context and the statistics of natural images. Supposing that you have an input patch (a region of an input image to a convolutional neural network) “x”, then there is a conditional probability distribution p(y|x) over the colours of the corresponding output patch y.
This distribution essentially takes context into account in the generation of the output colour. A colourisation neural network typically approximates the mode of this distribution: it has learnt that there is a probability that a particular part (patch) of a black and white input image should be a specific colour or range of colours, based on previous output patches that corresponded to similar input patches when the network was being trained. That is how black and white photographs, or videos, can be colourised.
A super-resolution network is solving a very similar problem in a similar way: in its case, it has learned to produce the most likely high-resolution output patch Y, given the context from a low-resolution input patch x.
The capability to upscale images has been around for a while now, so you may ask why do we need another method? Existing techniques include nearest neighbour, bilinear, and bicubic (cubic convolution) up-sampling, and these techniques have sufficed in most image and video upscaling applications to date. However, the crops of an upscaled output image shown below, highlight some undesirable artefacts produced when images are upscaled to larger resolutions in this way.
.png?width=984&name=MicrosoftTeams-image%20(19).png)
As you can see above, the crops of the output image contain artefacts called “jaggies” on the leopard’s whiskers, and the nearest neighbour algorithm also struggles to recreate the skin texture, causing pixelation. Bilinear and bicubic algorithms tend to over-soften the image to the point where it starts to look out of focus and lacking in detail.
The combination of these limitations, and a macro-trend for increased display resolution capabilities, while still maintaining current power budgets and performance, is seeding some very exciting innovation in this area.
Visidon is a Finnish company founded in 2006 with a talent for using AI-based software techniques to enhance still images and video content. It has developed a set of deep-learning-based super-resolution networks that can scale images and videos created at 1080p up to 4K (2160p) and 8K (4320p) resolutions. Three deep-learning-based super-resolution networks (VD1, VD2, and VD3) have been designed and trained, where the goal for each was to respectively deliver:
- very fast bicubic quality inferencing (VD1)
- fast and better than bicubic quality inferencing (VD2)
- highest quality super-resolution for still images (VD3).
How Imagination has helped deploy and accelerate these algorithms
Using super-resolution to increase the resolution of image and video content while delivering at least 60 frames per second takes serious compute, and that’s where Imagination can help. Our IMG Series4 AI compute engine with Tensor Tiling technology has been designed to provide low system bandwidth, high-inference rate execution of convolutional-based neural networks – the main algorithm found in Visidon’s set of super-resolution solutions.
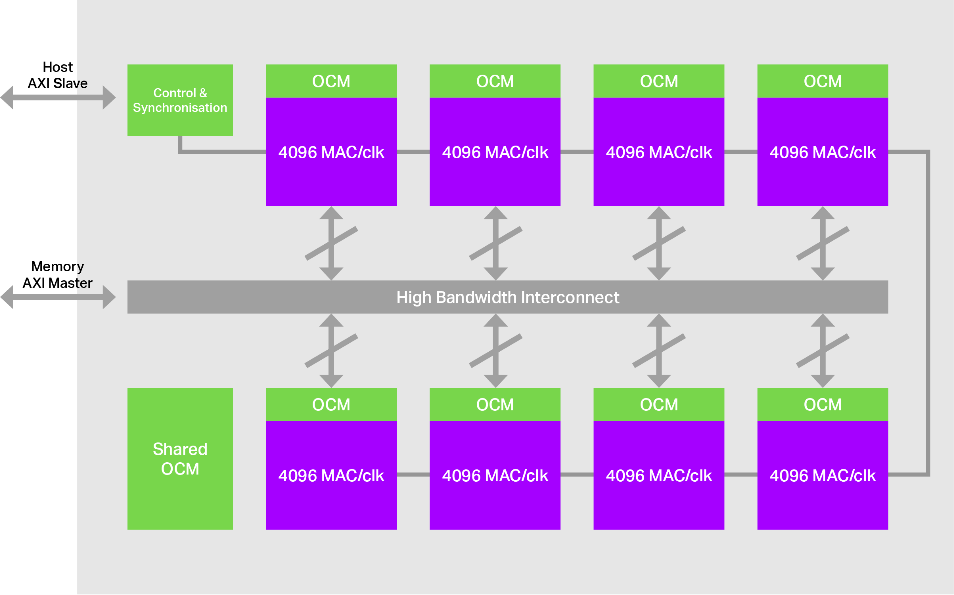 Figure 1. IMG 4NX-MC8, Imagination's scalable multicore architecture.
Figure 1. IMG 4NX-MC8, Imagination's scalable multicore architecture.
The combination of our multi-core architecture and patented Tensor Tiling allows for significant amounts of image and weight data to remain on-chip while being processed in parallel, producing scalable, powerful, super-resolution performance, as shown in the graph below:
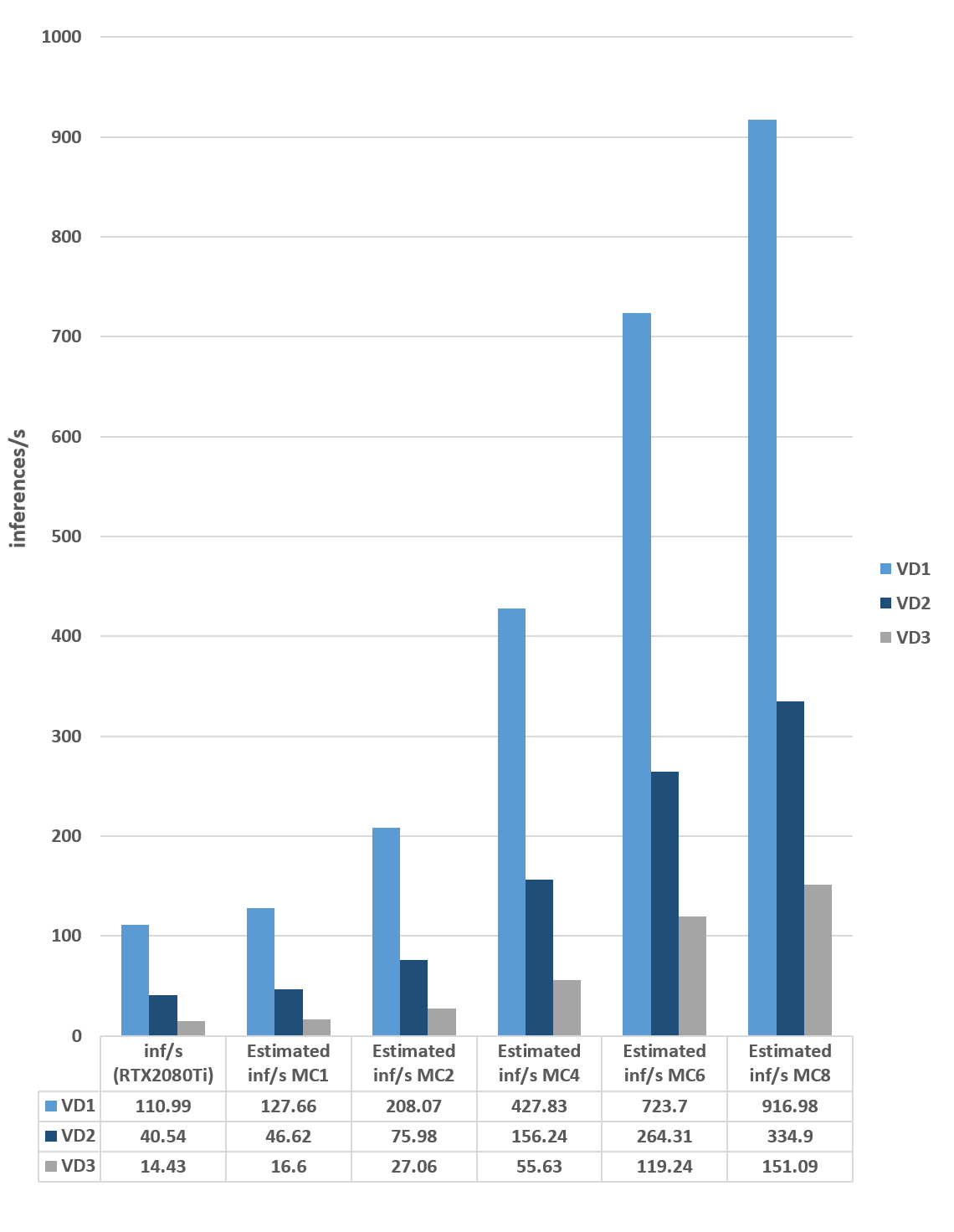 Table 1: Visidon Super-Resolution network performance on the IMG Series4 NNA compute engine (converting 1080p video to 4K resolution)
Table 1: Visidon Super-Resolution network performance on the IMG Series4 NNA compute engine (converting 1080p video to 4K resolution)
How Visidon measures visual quality
The quality of Visidon’s networks has been evaluated by expert and non-expert participants using random-blind evaluation where both sets of evaluators independently assigned a score to each of the seven output versions (three Visidon networks (VD1-3) and then lanczos4, bicubic, bilinear and nearest neighbour). A comparison of Visidon’s VD super-resolution network quality vs. existing non-deep-learning-based up-sampling algorithms can be seen in the table below:
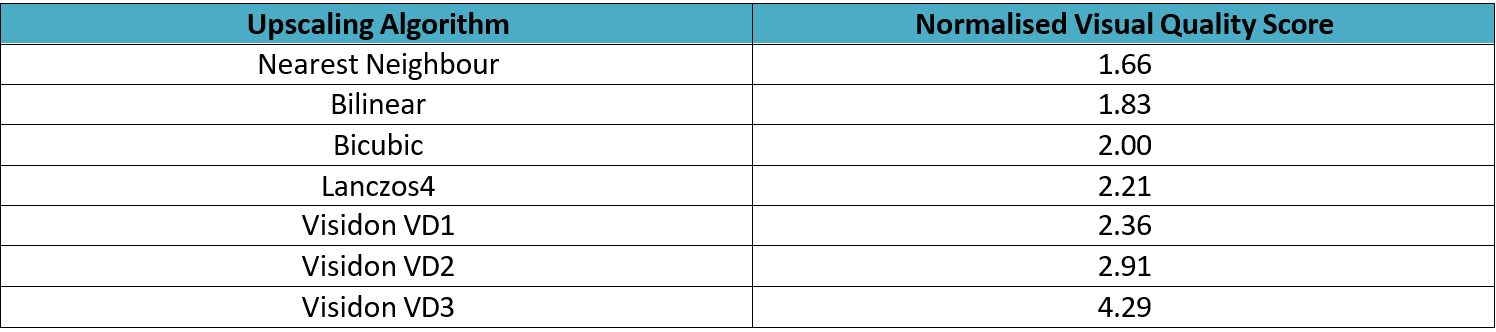
The evaluators had not seen the images or results of the networks before and were not allowed to discuss the results. The scores were then normalized between 1 and 5, where bicubic was given a reference score of 2.
And now the part you have been waiting for – the visual results!
So let us now look at the results from Visidon’s VD1, VD3, and VD3 networks, which can be deployed effectively on Imaginations Series4 NNA, with Tensor Tiling.
Note: Sample images are from the Flickr2K dataset which is free to use for commercial purposes and OpenCV library was used for lanczos4, bicubic, and bilinear and nearest neighbour upscaling so the results can be verified.
 The above image comparison highlights the outstanding quality of Visidon’s VD3 super-resolution algorithm, bringing in sharp, noiseless, clarity on all parts of the flower – particularly visible in the petal detail and the yellow stamens. The bicubic algorithm cannot handle the edges sufficiently for them not to be lost to smoothing. See also where the inner petals intersect the darker centre regions of the flower.
The above image comparison highlights the outstanding quality of Visidon’s VD3 super-resolution algorithm, bringing in sharp, noiseless, clarity on all parts of the flower – particularly visible in the petal detail and the yellow stamens. The bicubic algorithm cannot handle the edges sufficiently for them not to be lost to smoothing. See also where the inner petals intersect the darker centre regions of the flower.
.png?width=858&name=MicrosoftTeams-image%20(16).png)
Another great example of where foliage and the rock definition are preserved through appropriate sharpening in the Visidon network, which is simply lost in the smoothing of a bicubic upscale.
.png?width=852&name=MicrosoftTeams-image%20(17).png)
In this comparison, the detail and clarity of the micro feathers comes through with the Visidon’s VD2 network, which is impressive given that the input image in places, exhibits aliasing. The VD2 network recovers from this by preserving the complexity of the feather pattern, which the bicubic algorithm cannot. Detail on the beak and the small feathers glancing off it remain in focus with no visible staircase effect – which, albeit subtly, can be seen in the bicubic output image.
.png?width=861&name=MicrosoftTeams-image%20(18).png)
This image comparison highlights the baseline goal of Visidon’s VD1 network to beat bicubic upsampling in terms of quality while delivering very high inferencing performance. So, while VD1 produces the lowest perceptual quality in the evaluations, the output is suitably sharper than the bicubic upscale, allowing details on the feathers under the eye to be retained and noticeably more clarity of grain on the branch underneath the talon.

Here we see Visidon’s network adeptly bringing back the detail, lost from the bicubic upscale. Thanks to Visidon’s VD3 network, what would have been a very blurry crop of a small part of the original image comes alive with fine detail. Also, note the reflection detail on the water in the VD3 upscale. Incredible!
Conclusion
Before compute capabilities became available to super-resolve images and video in real-time, existing algorithms have satisfied viewers up to 1080p resolutions. But with the ever-increasing quality of 4K (and 8K) displays, the softening that goes on in non-deep learning algorithms doesn’t quite cut it for a new generation of high-resolution viewing.
Therefore, if upscaling techniques are employed to deliver low-resolution content to high-resolution screens, detail from the source images and videos must be preserved intelligently and contextually, to provide the most pleasing visual experience.
And the increased compute capabilities made possible by Imagination’s IMG Series4 NNA AI compute engine, which can deliver low-power, low-area and system-bandwidth-scalable convolutional neural network acceleration – make it the perfect platform on which to deploy Visidon’s state-of-the-art deep-learning-based super-resolution solutions.
You are going to go and watch Blade Runner now, aren’t you...?
Acknowledgements:
Thank you to James Imber, Senior Research Manager, IMG Labs, and Joseph Heyward, Senior Research Engineer, IMG Labs, for their support in developing this blog post.



