


Speech recognition has become more relevant in recent years: it enables computers to translate spoken language into text. It can be found in different types of applications, such as translators or closed captioning. An example of this technology is Mozilla’s DeepSpeech, an open-source speech-to-text engine, which uses a model trained by machine learning techniques based on Baidu’s Deep Speech research paper. We are going to provide an overview of how we are running version 0.5.1 of this model, by accelerating a static LSTM network on the Imagination neural network accelerator (NNA), with the goal of creating a prototype of a voice assistant for an automotive use case.
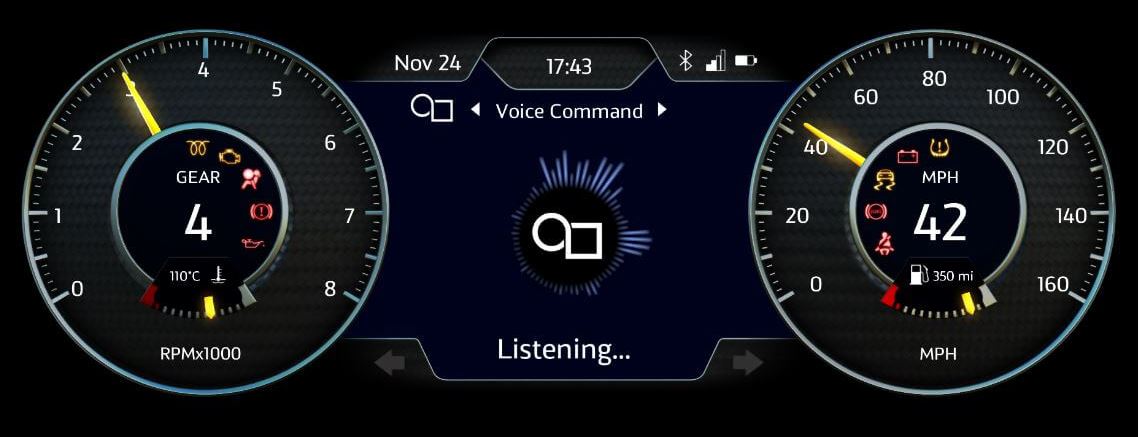 Example of a voice assistant for an automotive use case.
Example of a voice assistant for an automotive use case.
First, let’s consider tasks where data extends over time, for example, tracking people in a video, where someone can change his location as the frames run by. The problem some neural networks face, such as a typical object detection network, is that they have no memory of what happened in the previous inferences, so detecting a person in two consecutive frames doesn’t mean it will remember it is the same individual. This means that in some cases we need to be aware of data that occurred at different points in time since it influences the result. Because speech recognition is also a time series task, we will use a special type of neural network that is up to the challenge; a Recurrent Neural Network (RNN).
In order to remember things that occurred in the past, an RNN keeps a “hidden state”, which is a representation of previous information. This allows the flow of data through inferences and has an impact on the output. It is used in addition to the data we need (in our case, a portion of audio), and gets updated so that the next time step can use it. This way, the data that is being executed at a certain time has some knowledge of data that was previously processed. However, these networks suffer from short-term memory and work better with short data.
Long short-term memory (LSTM) networks are specific types of RNNs, which perform better with long sequences of data. They have a cell with additional operations that decide what information to forget, what to retain, and what to update. This is returned in our model as an extra output called “cell state”, which is also used as input in the next inference, in addition to the hidden state. Here is an overview of how the data is flowing through the network in our demo:
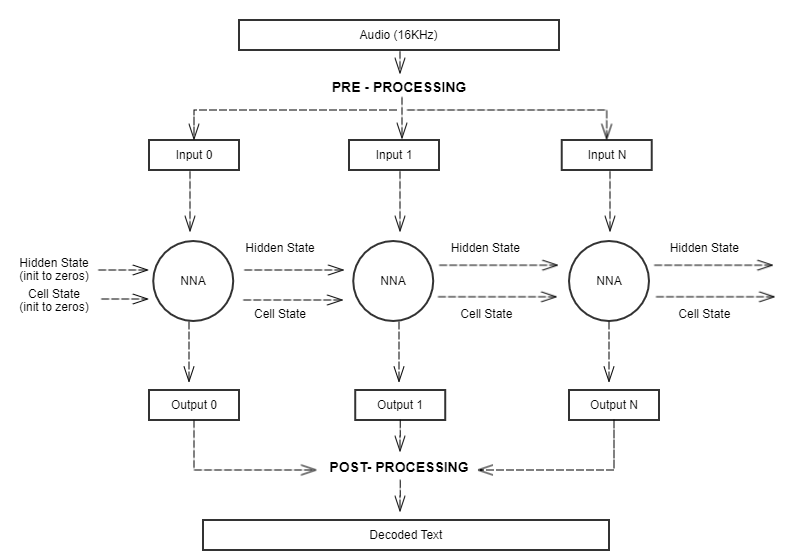 Data flow through a static LSTM network
Data flow through a static LSTM network
The operations happening inside LSTMs can be accelerated by an Imagination neural network accelerator, and for this demo, we are using it to run a static implementation of the network, that has been mapped to a format the NNA can read. The pre-processing and post-processing of data can be done separately on the GPU or CPU.
For the input source, we can use a live feed from a microphone or an audio file. But the network is expecting sequences of audio in the form of mel-frequency cepstral coefficients (MFCC), so the data needs to go through a series of transformations, such as; cutting it into multiple frames, evaluate the magnitude spectrogram of a short-time Fourier transform (STFT) for each frame, map it to the mel scale, and finally, obtain the MFCC coefficients as the discrete cosine transform (DCT) of the logarithm of the mel-mapped spectrum. Once we have done these steps, and because we are using a static unrolled version of an RNN, we need to move our pre-processed data along the time dimension, to only feed enough data each time we execute the network.
Apart from the source audio file, we need two states in order to maintain information over time; the cell state (state C) and the hidden state (state H). So, along with the audio data, these states are also used as input, and during execution, the cell state and the hidden state are updated and returned with the actual output of the inference, so they can be used in the next round. In summary, each inference needs three inputs and returns three outputs – this way it can maintain information over time.
The output of one inference contains the probability of each character of the alphabet happening at a certain time step (only one is the highest probability). After the NNA has returned all the outputs for all the MFCC coefficients, we finally have what we need to do post processing. In order to convert our probabilities into actual text, we use a connectionist temporal classification (CTC) decoding algorithm and it is also possible to tune this to improve performance on specific sentences.
For this demonstration, we are using the decoded text to simulate a voice assistant for a car. With the help of OpenGL® ES, we have a user interface resembling an automotive digital cluster, and by using a microphone as the source of the audio we can speak commands such as “increase the volume”, “check battery levels” or “display navigation”, which the assistant will recognise and then display the appropriate results.
 Example of a voice assistant processing the commands it heard (above)
Example of a voice assistant processing the commands it heard (above)
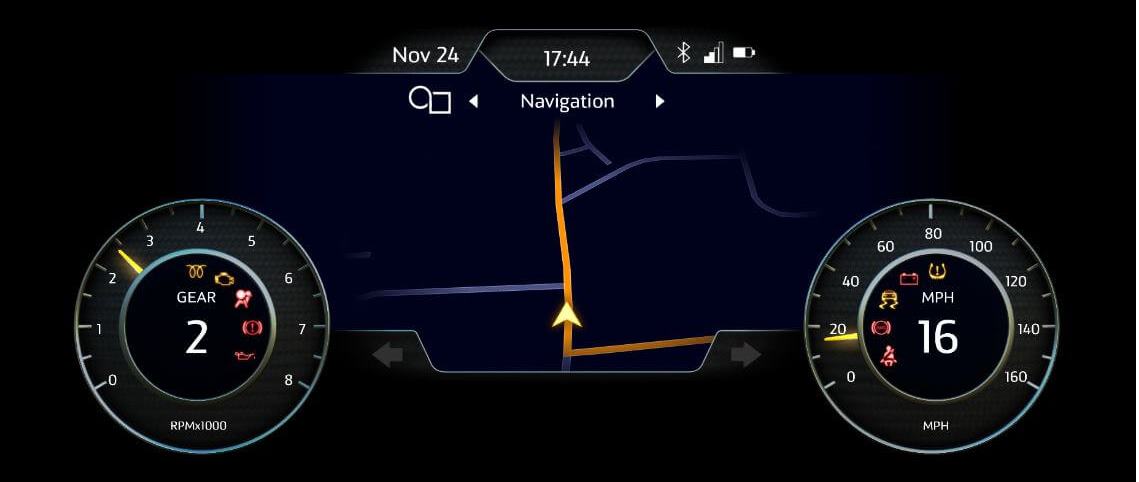 Voice assistant performing an action
Voice assistant performing an action
Regarding performance, each inference of this network can process a segment of 20 milliseconds of audio. If we use a live stream of audio, we have to process 50 segments of audio in one second. At this rate, our NNA only uses 6.1% of the core capacity running an inference (1.22 ms) at eight tera operations per second (8 TOPS), either for one or for up to 16 channels of audio in parallel. When using 100 % of the capacity, it could run up to 262 independent channels. If running at 0.8 TOPS, the inference time is 4.90 ms, and uses 24.5% of the core for live audio, or up to 65 channels when working at 100% of capacity.
| Static LSTM network | 8 TOPS | 0.8 TOPS |
| Inferences per second (at 100% capacity) |
820 inf/s | 204 inf/s |
| Time to process 20 milliseconds per step (1 – 16 channels) |
1.22 msec (6.1 % capacity) |
4.90 msec (24.5 % capacity) |
| Total channels of audio that can run in parallel | 262 (at 100% capacity) |
65 (at 100% capacity) |
As technology improves, AI systems get more complex, and the need to accelerate these operations increase. The performance of Imagination’s NNA makes it an efficient tool for running these types of networks, and it allows developers to create interactive software that can handle speech recognition, something that will be used for many years to come.
If you want to talk more to us about what our NNA can do for you then do get in touch.



