

Over the last few years the concept of virtualization – separating software from the hardware on which it is run – has become familiar to many. In this post, we will describe what virtualization is, and look how it works in PowerVR GPUs, and explain how this provides great benefits to various markets, in particular to automotive.
On desktops, virtualization enables a computer to run more than one operating systems concurrently, so that, for example, a developer can run a Linux ‘guest’ operating system on a Microsoft Windows host machine, whereas in the enterprise space, it’s often used to consolidate workloads in order to decrease CapEx and OpEx. In embedded platforms, the primary purpose is to lower costs while also ensuring security through separation.

When it comes to GPUs, virtualization delivers the capability of supporting multiple operating systems running at the same time, each capable of submitting graphics workloads to the underlying graphics hardware entity. This is becoming increasingly important in the automotive space. For example, it enables critical systems such as the advanced driver assistance system (ADAS) and digital dashboard to be run separately and securely by placing them in entirely separate domains.
To break it down, a virtualized GPU will run the following:
- Hypervisor: This is fundamentally the software entity which presents the guest operating systems with a shared virtual hardware platform (in this case the GPU hardware) and manages the hosting of the guest operating systems.
- Host OS – the operating system with a full driver stack and higher control capabilities to the underlying hardware compared to the guest operating systems.
- Guest operating system (Guest OS): the virtual machine with an OS, hosted by the hypervisor. There can be one or more guest OSs that shares the available underlying hardware resources.
Hardware virtualization vs. paravirtualization
PowerVR has featured advanced, full hardware virtualization since the Series6 range of GPU cores, and it has been enhanced further in Series8XT, the detail of which we will delve into later in this post. By full virtualization, we mean that each guest OS runs under a hypervisor and has no awareness that it is sharing the GPU with other guests and the host OS. Each guest generally has a full driver stack – and can submit tasks directly to the underlying hardware, in an independent and concurrent manner. The advantage of this is that there is no hypervisor overhead in handling task submission from the different ‘guests’ and this, in turn, reduces the latency in task submission to the GPU, leading to higher utilisation.
This differs to a paravirtualization solution in which the guest OSs are aware that they are virtualised and are sharing the same underlying hardware resource with other guests. In this scenario, guest operating systems are required to submit tasks via the hypervisor and the entire system has to work together as a cohesive unit. The disadvantage of this solution is a high hypervisor (running on CPU) overhead and long latencies in task submission, potentially reducing the effective utilisation on the underlying GPU hardware. Also, there is a need to modify the guest OSs (add additional functionality) to enable them to be able to communicate via the hypervisor.
GPU virtualization use cases:
There are a number of use cases for GPU virtualization and those listed below are focussed on the embedded market.
- Automotive
- Digital TV (DTV)/set-top box (STB)
- IoT/wearables
- Smartphone/tablets
The virtualization we are talking about in this blog post focuses on automotive, as this a market where virtualization will have many benefits. It has specific requirements, that make it one of the more complex markets to address and for more on this, you can refer to our white paper.
Why does the automotive market need virtualization?
GPU virtualization is becoming a must-have for the automotive industry. The majority of the Tier 1s and OEMs are opting to include more ADAS functionality, while in new cars multiple high-resolution displays are becoming commonplace.
As vehicles move toward greater autonomy ADAS functionality is therefore increasing. These functions are computationally complex and the massive parallel computing capabilities of modern GPUs make them a good fit for handling these tasks. Concurrently, there is an increasing trend towards higher resolution displays at for dashboard cluster and infotainment, both in the dash and the rear seats, and HUDs in the windscreen.
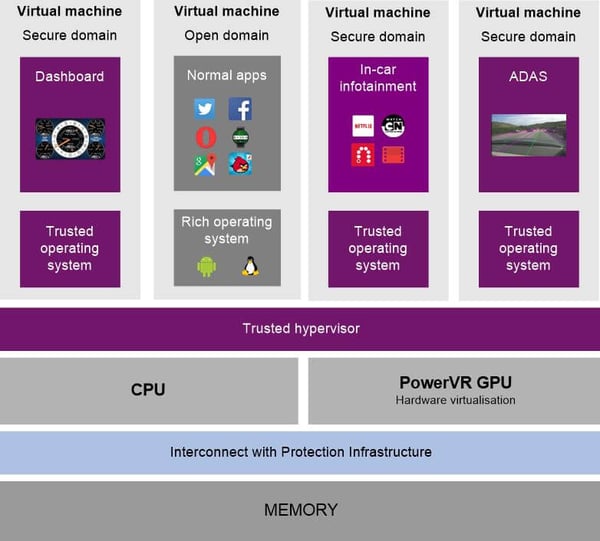
An illustration of an automotive system with multiple applications supported in a virtualized environment.
Geared for automotive
So why are PowerVR’s virtualization capabilities so suitable for automotive? Essentially, it’s because it offers a number of features that solve a number of problems, such as hardware robustness for maximum security and quality of service to ensure sustained performance, while ensuring maximum hardware utilisation of the hardware.
Isolation
First, let’s look at basic isolation, This is the isolation between the different OSs and their corresponding applications, which is used to provide security through separation of applications, and is, of course, one of the fundamental benefits of virtualization.
This feature is demonstrated in the video below. It shows an OS application, a cluster displaying critical information such as speed, warning lights etc. and next to it a navigation app, which is a less vital OS application The satnav application is made to crash (artificially), followed by a ‘kernel panic’ and a full reboot of the less critical OS. The crucial aspect to note is that this doesn’t affect the dashboard cluster application running on the critical OS; it continues to render completely uninterrupted. Also, note that once this guest OS reboot has completed it is able to again start to seamlessly submit jobs to the GPU.
Quality of service: guaranteed level of performance
One of the key requirements of the automotive industry is the requirement for one or more critical applications/OS to be guaranteed sufficient resources to be able to deliver the required performance. On PowerVR this is achieved by prioritisation mechanisms, wherein a dedicated microcontroller within the GPU handles scheduling and honours the priority set for each OS (and, if needed, the priority of each application/workload within the OS). When a higher priority OS’s workload is submitted to the GPU, the lower priority OS’s workload is context switched out.
In simplistic terms, ‘context switching’ is where the current operation is paused at the earliest possible point and the required data is written out to enable the resuming of the operation at a later point in time.
The earliest possible point for the Series 6XT (the first generation of PowerVR GPUs which supported full hardware virtualization) platform being used in this demonstration is:
- Geometry processing: draw call granularity
- Pixel processing: tile granularity
- Compute processing: workgroup granularity
Once the higher priority OS’s workload has been completed, the lower priority workload is resumed and completed. This feature helps ensure that the critical higher priority workloads get the required GPU resources to guarantee the required performance.
This is demonstrated in the video below. In this, there are again two OSs running on the GPU, one which is deemed as critical (running the dashboard cluster app) and the other as less critical (running the navigation app).
In the first part of the video, the critical OS (on the left) is set to high priority with a required level of performance of 60fps (frames per second). This is then increased to 90fps (27 seconds in) and then 120fps, and, as can be seen, the fps of the less critical OS navigation app drop accordingly. When the target fps is dropped to just 10 and 20fps there is a corresponding increase in the navigation application framerate.
(Note that the workload complexity of the navigation app is much higher than the cluster app, hence the corresponding increase in frames per second is relative, not directly comparable).
Finally, when the required level of performance of the critical OS is set to “max possible” it consumes all the GPU resources due to its priority being higher and, as expected, the navigation app rendering completely stalls (1min 40s).
Other virtualization features related to the automotive industry in our GPUs, such as denial of service are beyond the scope of this blog, so for more detail, again, please refer to our white paper.
The benefit of hardware virtualization
In the following demonstration, a key benefit of full hardware virtualization described in the earlier section is demonstrated: namely the effectiveness in scheduling tasks from different OSs on the GPU, while maximum utilisation and performance.
In this video the workloads submitted from the two OSs are the same, to make the results directly comparable.
Initially, both the OS’s workloads are given the same priority, hence are scheduled on the hardware (by the dedicated scheduling microcontroller within the GPU) in a round-robin fashion. As seen, they are sharing the GPU resources equally and are achieving the same performance (quantified in frames per second). In the second part of the video, the performance of the app from in the OS on the left is artificially limited to a maximum frame rate, which is varied every few seconds. As you can see, there is a corresponding proportional increase in the performance (fps) of the OS app on the right, which doesn’t have a fixed frame rate set. This demonstrates the scheduling efficiency and the corresponding maximum utilisation achieved in a virtualised environment – i.e. achieving maximum performance from the virtualised GPU hardware.
Taking it a step further: Series 8XT enhanced virtualization
The first PowerVR series to support full hardware virtualization was Series6XT, of which a Series 6XT platform was used in all the above videos/ demonstrations. In this section, we are going to look at how it has been further enhanced for Series8XT, with a number of new features and enhancements.
Finer grain context switching
With Series8XT the context switching can be executed at a finer granularity, hence ensuring even faster context switch out of the lower priority workloads and scheduling of higher priority workloads. The context switch granularity is now at:
- Vertex processing: primitive granularity
- Pixel processing: sub-tile, or worst case back to tile granularity
Per data master killing
In the case where the lower priority app doesn’t context switch out within the defined timeframe, there is a DoS mechanism to per data master kill or soft reset the app, depending on the data master (compute, vertex or pixel processing). Previous generations supported only compute killing, whereas vertex and pixel processing required a soft reset, thus affecting the high priority workload if it was being run in overlap with the unsafe lower priority application. In Series8XT, now all data masters can be killed, ensuring that even if a high priority/critical workload overlapped with an application that needed to be evicted, it wouldn’t be affected.
Per SPU workload submission control
With this feature, a particular application can be given its own dedicated scalable processing unit (SPU) within the GPU to execute its workloads. This, for example, can be beneficial for long-running compute-based ADAS applications in automotive, wherein the application can be run on its own dedicated SPU uninterrupted, while other applications, potentially from other OSs, use the other mechanisms (for example, prioritisation based on context switching for higher priority tasks) to share the remainder of the GPU resources.
Tightly integrated second-level MMU
Previous generation GPUs had a first-level MMU, hence requiring the SoC vendor to design and implement the second-level/system MMU or a similar mechanism at the SoC level to support virtualization. Series8XT now has an integrated second level MMU within the GPU, which brings about the following benefits;
- Optimally designed and tightly coupled with first-level MMU, delivering low latency and improved efficiency
- Reduced effort for the SoC vendor, resulting in faster time to market
- Corresponding isolated software for the entity available in the hypervisor
- Enables the support of full/two-way coherency support, delivering improved performance and reduced system bandwidth
- Inherently enables higher level of protection in a virtualized environment and more fine grain (page boundary) security support
Conclusion
So there you have it. The hardware virtualization present in PowerVR GPUs is highly efficient and ideally suited to meet many of the requirements of the automotive industry. Already a proven feature, our latest Series8XT GPUs enhance it further to help make next-generation in-vehicle infotainment and autonomous driving a reality; safely and cost-effectively.
To find out more about where the market is going read this article to understand what Imagination’s solutions are for this market as a whole and if you want to get an even deeper understanding of PowerVR’s virtualization solution please refer to our white paper on the subject.



