


Back in September Imagination changed the game for embedded AI acceleration with the introduction of the Series2NX neural network accelerator (NNA) and today we are proud to announce two cores in the range: the PowerVR AX2185 aimed at the premium markets, and the AX2145 for the mid-range. (We go into more detail about each below).
As we explained in our post at the time, neural networks are becoming increasingly prevalent as a tool for solving problems and powering new types of applications across a wide range of industries. Do check out our blog post if you’d like a simple explanation of what neural networks are and how they work.

Today, many of the devices you use every day will make use of a neural network. They power the search function in the photo application on your smartphone and are used to identify you so you can unlock your phone with your face. They are how your number plate is recognised when you enter or leave a congestion zone and they are clever enough to detect a person’s body language – ideal for surveillance systems. They could be in a camera-enabled AV system that identifies you and offers personalised content and in automotive, performing tasks such as lane departure warning and driver alertness monitoring, to name but two. It’s also been proven that neural networks are better than humans at detecting skin cancers – the uses are wide and varied.

While neural networks are trained offline, when it comes to inference – the running of these networks to identify and process objects in real-time – there is a need to have this technology available in edge devices, rather than having the processing take place in the cloud. Take just one example: drones. They can fly in excess of 150mph and a neural network can power the collision detection system. However, without dedicated hardware to process the images, the drone would need to see objects 10-15 metres ahead to have a chance of avoiding obstacles. The cloud is not a suitable solution due to the latency it would take to send and receive the information and the bandwidth required. A drone equipped with a dedicated PowerVR NNA could travel at 150mph and be able to avoid obstacles under one metre away, improving responsiveness and safety and enhancing the creative possibilities for their use.

We see dedicated neural network hardware as the next step in SoC integration. In the 1980s a maths co-processor was available as an addition to supplement the early desktop CPU, but soon became a standard part of the design. While many of these compute tasks have moved from the CPU to the GPU, these are still not the most design-efficient tools for the job and placing them on dedicated local hardware is the logical solution. The performance advantages are clear. Searching 1,000 photos using a premium GPU takes 60 seconds – but just two on our NNA. You could also use 1% of battery life to sort images – but the NNA can process 428,000. That’s pretty compelling.
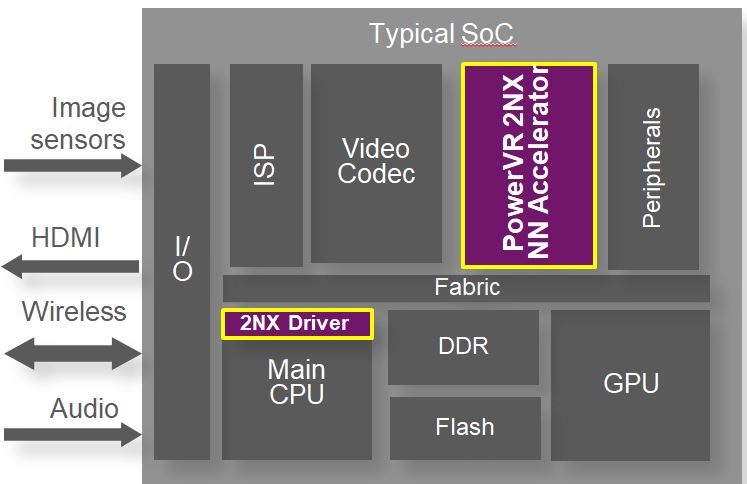
Our Series2NX accelerator launched in September was built from the ground up for neural network inferencing and is the highest performing solution in the industry. We also offer support for all the major convolutional neural network layers such as Inception and ResNet and frameworks such as Tensorflow and Caffe2 and PyTorch.
A key differentiator of our solution is the fact that it offers flexible precision. Using a trained network consisting of 16-bit data it can achieve very high levels of accuracy. However, training a network at lower precision means that for many purposes high levels of accuracy can still be maintained, but with the advantage of significantly reducing power consumption and requiring less bandwidth. In the real-world, this makes it cost effective and practical to integrate an NNA into embedded devices such as smart cameras and smartphones. Read our blog post to find out more about the process and benefits of training a network for efficient inference.
The chart below demonstrates the benefits of this precision flexibility. In a nutshell, with 4-bit precision, you can slash the power and bandwidth (memory) requirements, with a mere 1% drop in accuracy, which in most cases will have no appreciable impact on device effectiveness in the real world.

The PowerVR AX2185
Our Series2NX has already found success in the market with multiple licensees and today we are expanding the choice in the market. First, we are enhancing our original core in the form of the PowerVR AX2185 and second, releasing another version, the PowerVR AX2145. A key new feature in both cores is the addition of hardware support for the Android NN API, enabling developers to bring deep learning-based applications to a large market of Android-based devices.
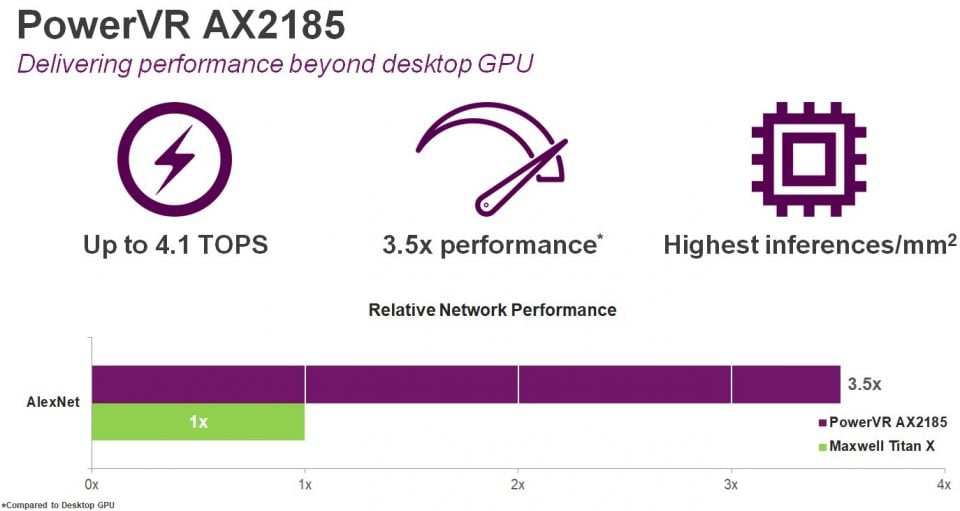
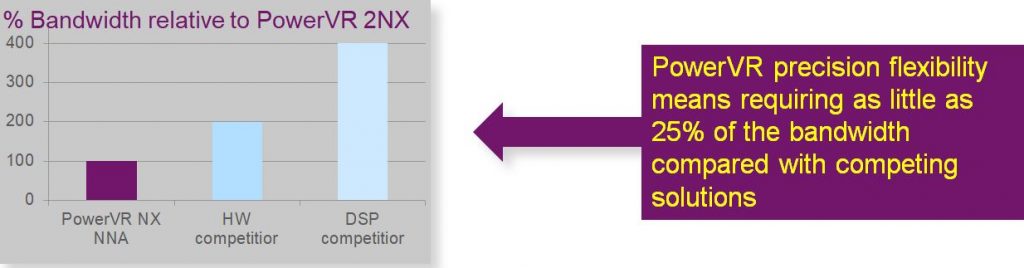
The PowerVR AX2185 is aimed at the higher-end of the embedded market in terms of its raw performance. With eight full-width compute engines the AX2185 delivers up to 4.1 Tera Operations Per Second (TOPS) offering the highest performance per mm2 in the market. In fact, this level of performance is 3.5 times the performance of recent desktop GPUs. This makes it a much more enticing prospect for those companies that are currently using power-hungry full-fat desktop GPUs for neural network inferencing, particularly in the automotive space. Compared to competitors offering competing hardware solutions, using a network based on 4-bits of data, the AX2185 will require just 50% of the bandwidth. When compared to DSP-based competitors the bandwidth requirement is 75% lower.
While premium devices already sport features such as face unlock, we are seeing that these capabilities are rapidly moving down the food chain. Device manufacturers are looking to offer this functionality at lower price points. Obviously, consumers want to pay less for their devices but still enjoy the benefits such as smart cameras for home security and face unlock on their smartphones. Yes, they want to have their cake and eat it.
The PowerVR AX2145
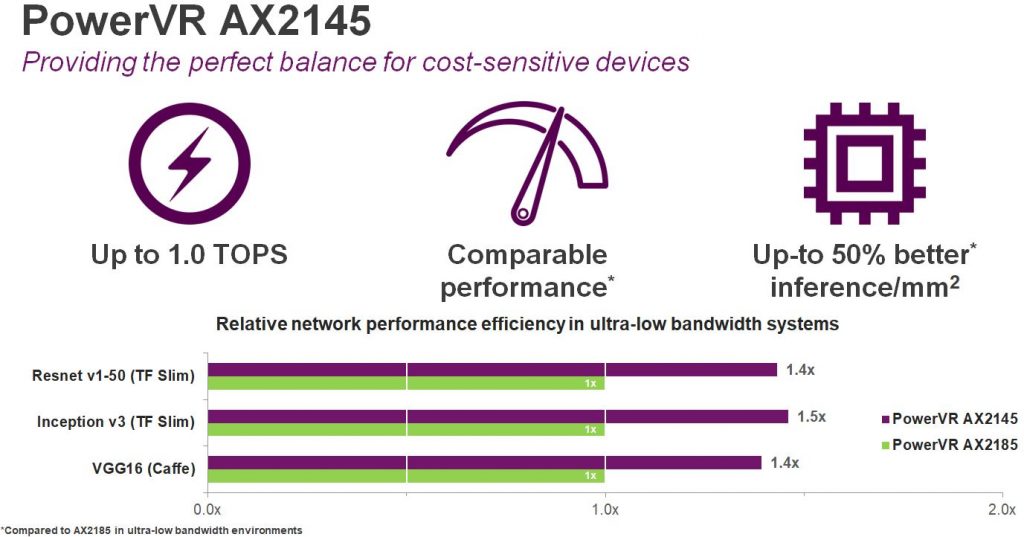
So how to maintain that experience in memory constrained devices? The answer is the PowerVR AX2145. This trades overall performance for performance efficiency. Its highly tuned tensor processing and convolution engines combined with an optimised core memory infrastructure can deliver outstanding maximum performance of 1 TOPS, but with a 50% better inference performance per mm2 than the AX2185 in systems with low peak memory bandwidth (as measured in GB/s). We’re really proud of this balance of performance and efficiency and we think it’s a really smart choice for cost-sensitive devices.
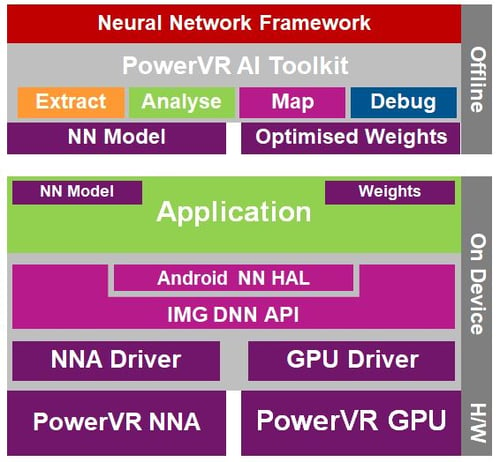
Of course, hardware alone does not make a solution. We offer a PowerVR AI toolkit, which simplifies the deployment workflow of our customers, provides easy debugging and network analysis and enables the optimisation of trained networks. Our API support includes the IMG DNN and Android DNN providing seamless operability between the GPU and NNA.
Conclusion
With the introduction of these two new cores, we are enabling new levels of intelligent applications to consumers through the addition of low-cost AI capabilities on edge devices. With these cores, developers will have access to devices offering all the performance they need to create applications that fulfill the promise of the AI revolution and we look forward to the improvements that they are sure to bring across markets such as smartphones, smart cameras and automotive. The possibilities are endless and the only thing needed is a little Imagination.



