


Research into neural network architectures generally prioritises accuracy over efficiency. Certain papers have investigated efficiency (Tan and Le 2020) (Sandler, et al. 2018), but quite often this is with CPU- or GPU-based rather than accelerator-based inference in mind.
In this original work from Imagination’s AI Research team, many well-known classification networks trained on ImageNet are evaluated. We are not interested in accuracy or cost in their own right, but rather in efficiency, which is a combination of the two. In other words, we want networks that get high accuracy on our IMG Series4 NNAs at as low a cost as possible. We cover:
- identifying ImageNet classification network architectures that give the best accuracy/performance trade-offs on our Series4 NNAs.
- reducing cost dramatically using quantisation-aware training (QAT) and low-precision weights without affecting accuracy.
Network architectures for efficient inference
We explored the trade-off space for different ImageNet classification networks measured using several costs, namely:
- Inference time (seconds per inference)
- Bandwidth (data transferred per inference)
- Energy per inference (Joules per inference)
In each case, we are interested in networks that give the highest accuracy at the lowest cost. These networks are shown below with their accuracies and costs, averaged across a variety of single-core configurations of our Series4 NNAs, with different on-chip memory (OCM) sizes and external bandwidths. The networks were quantised to eight bits without QAT.
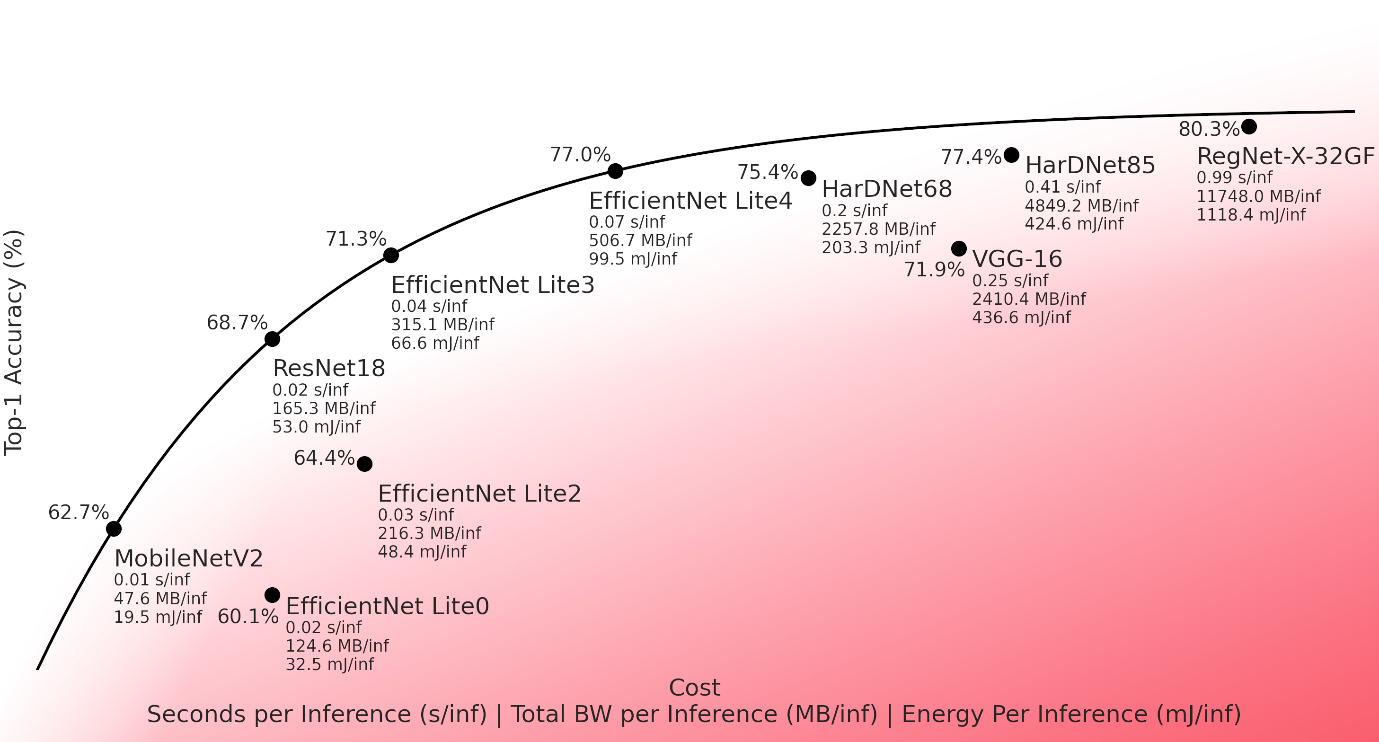
Figure 1: Trade-off line with recommended networks. We illustrate the accuracy/performance trade-off for a range of backbone networks mapped and verified on IMG Series4. We define a trade-off line for the optimal selection of the backbone for developer purposes. The red region shows the area of poor trade-off which is decaying as you are approaching the trade-off line. The least optimal network would appear in the bottom-right corner when the most optimal networks will lay on the line.
The graph shows the trade-off space between top-1 accuracy and cost of execution measured in seconds, bandwidth and energy per inference. Networks located towards the top-left of the graph are more efficient than networks located towards the bottom-right. Those networks closest to the top-left of the graph are identified as being the most efficient for execution on Series4 NNAs. We fit a “trade-off line” to these points, with suboptimal networks below it.
The networks on the trade-off line outperform other networks tested on our hardware, and give a good range of performance points in the efficiency trade-off space, ranging from fast/low-accuracy (MobileNet v2) to slow/high-accuracy (EfficientNet Lite v4).
When deploying on Series4, a network architect might consider whether one of these networks could be used as a basis (e.g. a backbone for an object detector). For example, VGG-16 (Simonyan and Zisserman 2015) is a popular backbone, but it appears below the trade-off line on the graph, indicating that for the achieved accuracy it is expensive in terms of inference time, bandwidth and power consumption. Instead of VGG-16, EfficientNet Lite v3 could be chosen to achieve the same accuracy at much greater efficiency.
We also noted diminishing returns when attempting to maximise accuracy. For example, the very large RegNet-X-32GF (Radosavovic, et al. 2020) achieves the highest accuracy on Series4 of all networks we analysed, but only at a high cost.
Low bit-depths and efficient inference
We also investigated a means of improving the efficiency of networks on our Series4 NNAs. One excellent way of achieving this is using QAT to reduce the bit depths of the networks, allowing for more efficient inference. Imagination neural network accelerator hardware supports low-precision formats for weights, which we exploit in this work. This has multiple advantages, including fewer hardware passes, denser memory utilisation and lower bandwidth consumption. We mapped QAT-trained neural networks with 8-, 6- and 4-bit weights onto our Series4 NNAs and measured the changes in performance. 8-bit data was used for data throughout.
The results shown below are for networks running on a single-core Series4 NNA with 1MB of OCM and 12GB/s of external bandwidth, and an 8-core Series4 with a total of 88MB of OCM and 115GB/s of external bandwidth. Lower weight bit depths significantly improve inference efficiency, particularly where bandwidth and memory are dominated by the network weights (as in VGG-16, for example). The efficiency improvements are generally most marked where bandwidth and memory are more limited.
Improvement in seconds per inference
One core, low bandwidth, low memory
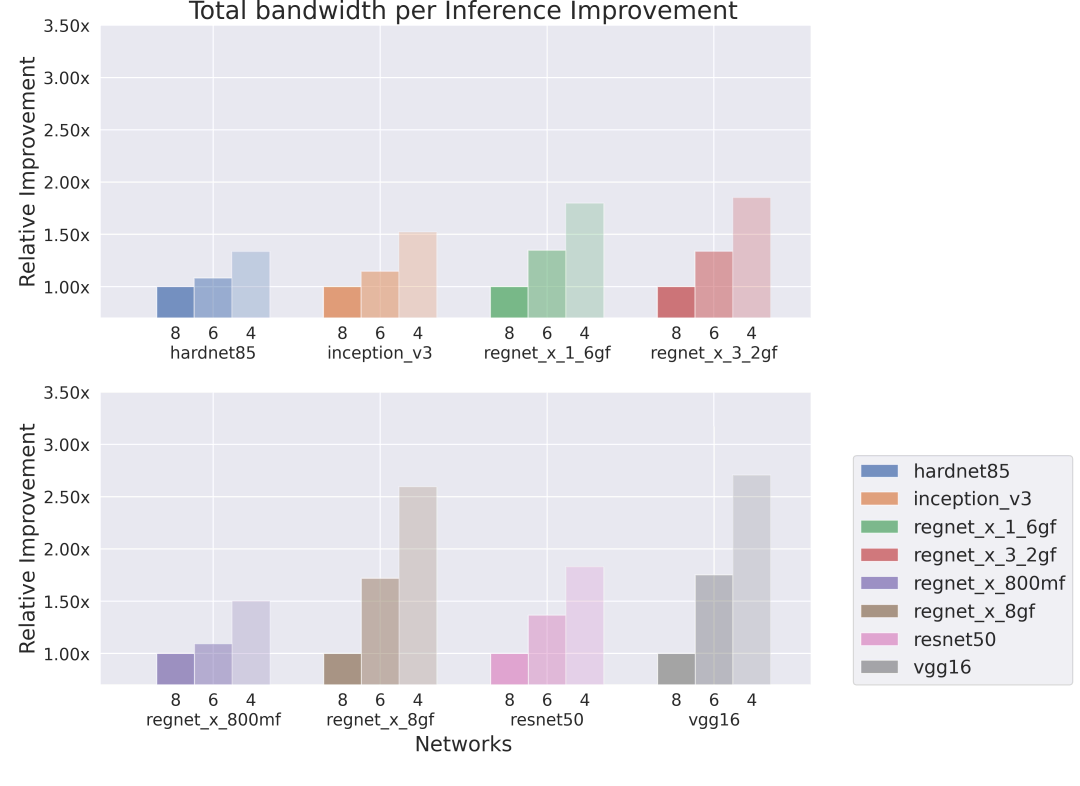
Figure 2: Relative improvement in seconds per inference executed on a single-core IMG Series4.
Significant improvements were observed in weight-heavy architectures, i.e., VGG-16, HarDNet85 (Chao, et al. 2019)and ResNet50 (He, et al. 2015). On the other hand, RegNets with more compact group convolutions achieve a smaller boost from QAT when running on high-bandwidth hardware, but we still achieve an additional 25-50% in inferences per second on low-bandwidth hardware.
Eight cores, high bandwidth, high memory
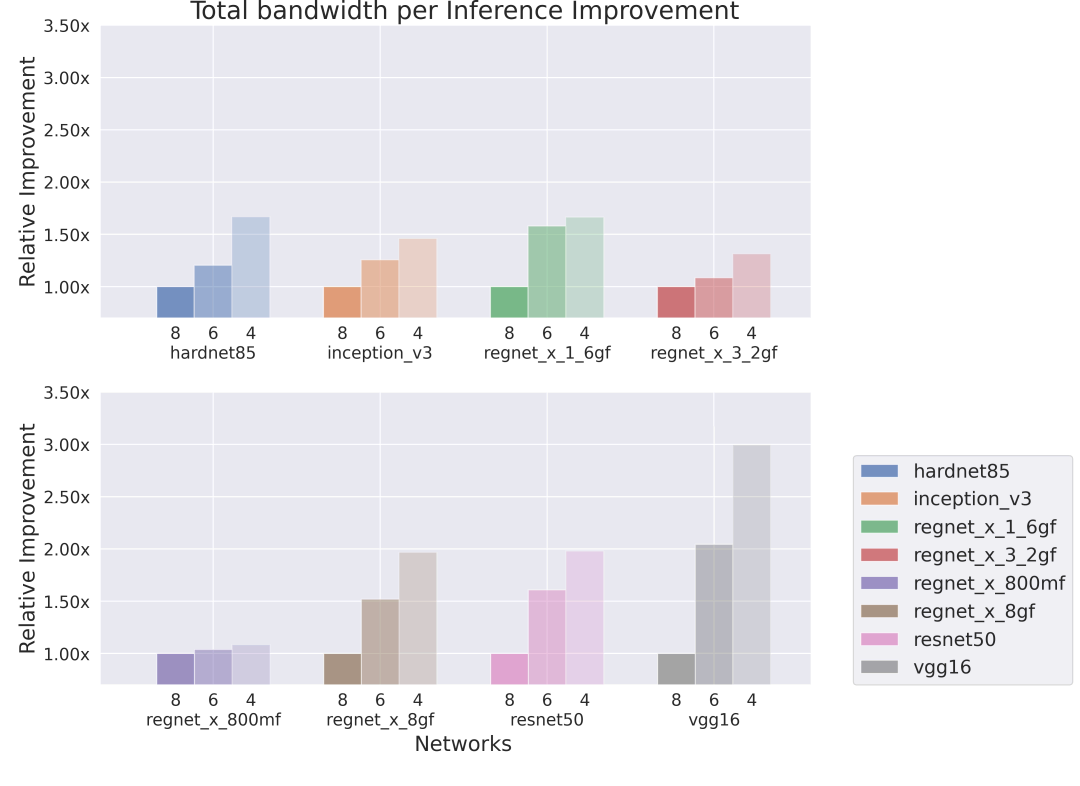
Figure 3: Relative improvement in seconds per inference executed on 8-core Series4.
Networks executed on 8-core Series4 are less bandwidth-limited and more compute-limited, which results in smaller gains in seconds per inference as we compress the network to 6- or 4-bits.
Improvement in memory transferred per inference
One core, low bandwidth, low memory
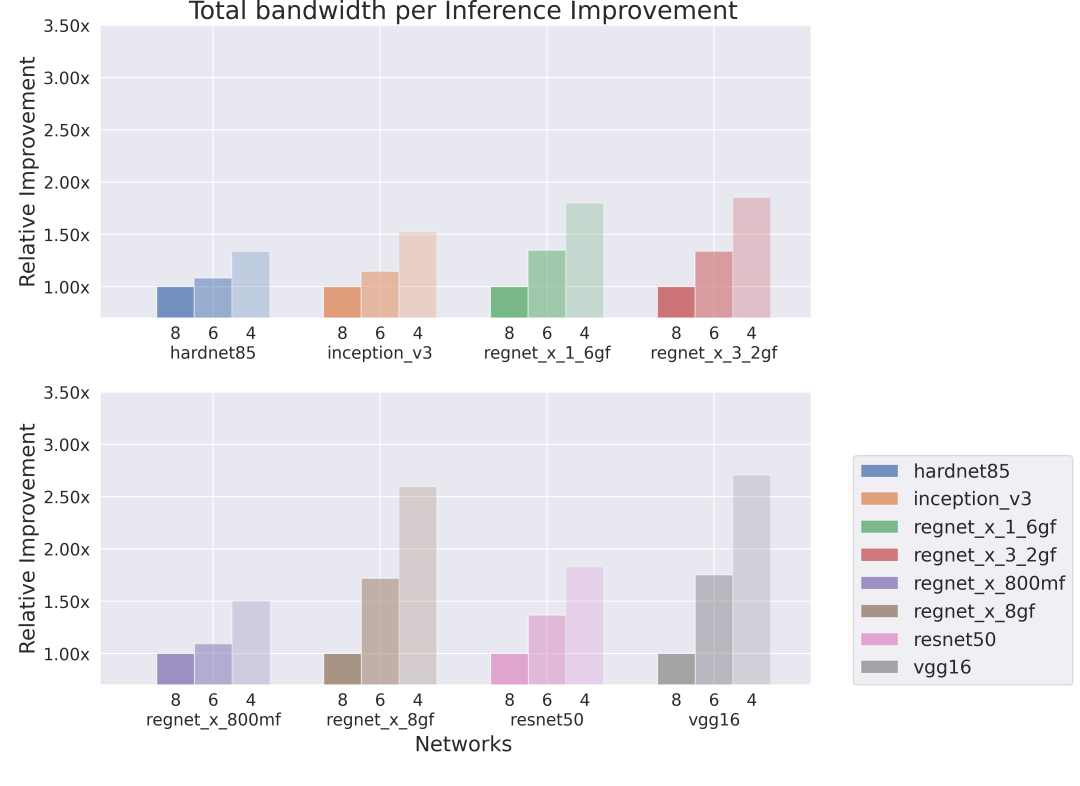
Figure 4: Relative improvement in total bandwidth per Inference executed on a single-core Series4.
Figure 4 (above) illustrates the reduction in total bandwidth with RegNet X 8GF and VGG-16 reduced to less than 2.5x of their original bandwidths.
Eight cores, high bandwidth, high memory
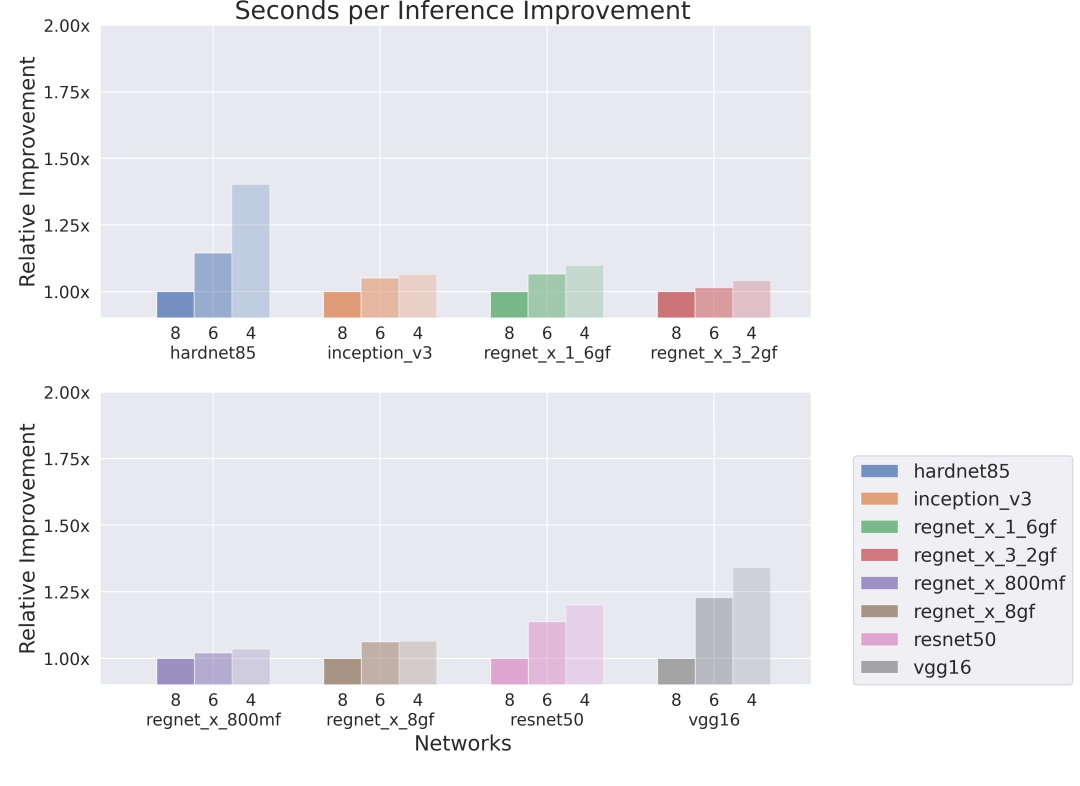 Figure 5: Relative improvement in total bandwidth per inference executed on 8-core Series4.
Figure 5: Relative improvement in total bandwidth per inference executed on 8-core Series4.
Improvement in energy per inference
One core, low bandwidth, low memory
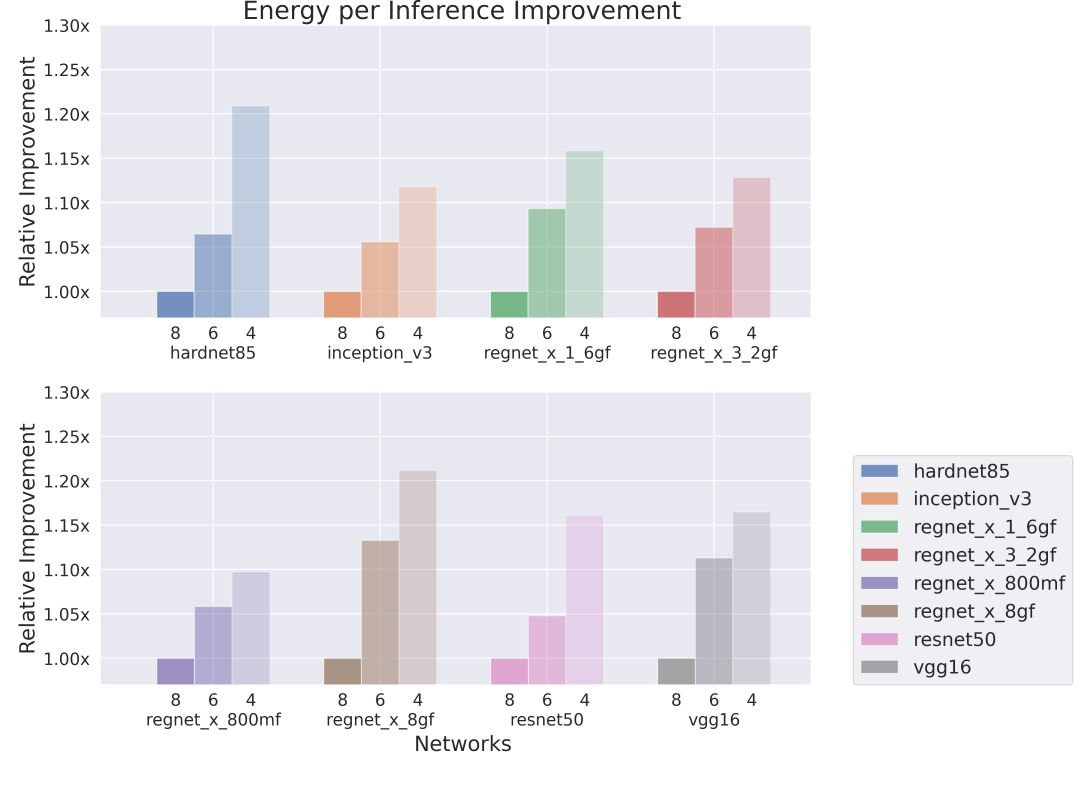
Figure 6: Relative improvement in energy per Inference executed on a single core Series4.
Eight cores, high bandwidth, high memory
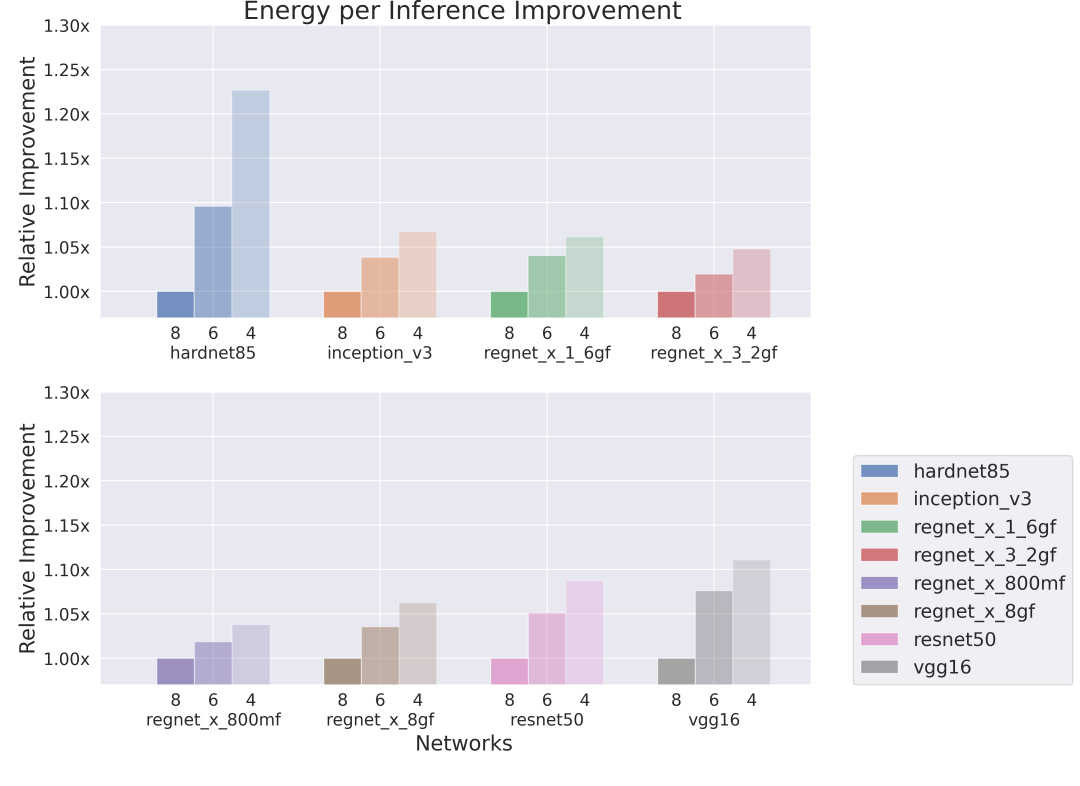
Figure 7: Relative improvement in energy per inference executed on 8-core Series4.
Accuracy
In most cases, networks with 8-bit and 6-bit weights have accuracy similar to the original 32-bit floating-point network. Those with 4-bit weights have a somewhat more significant drop in accuracy. Bit-depths were fixed throughout the entire network in these experiments. Recent research from Imagination shows that allowing the network to learn the bit-depths of weights can result in a lower overall network size without sacrificing quality, and we expect this to help significantly with performance in these cases too. Additionally, we observed that networks with large weights and lack of group convolutions are more robust to compression resulting in a smaller accuracy drop. Please note that the same weight bit depth was used for all layers in the network, and we expect higher accuracies from adaptive bit depths (Csefalvay 2022).
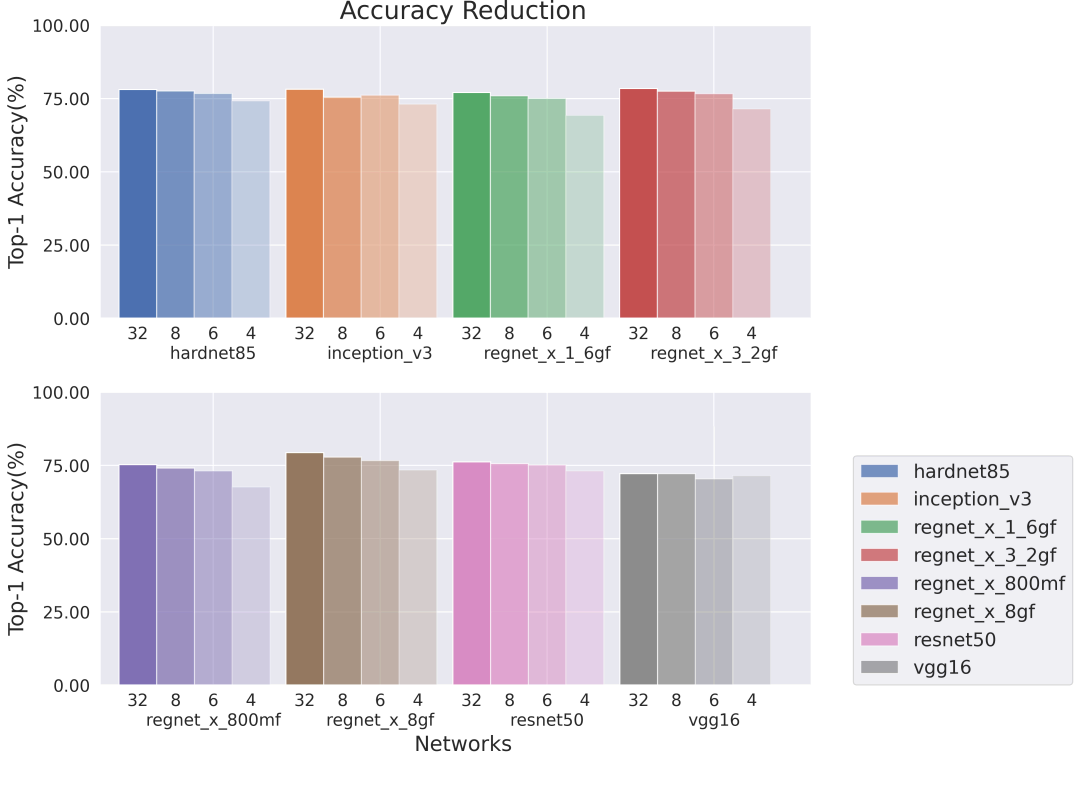
Figure 8: Accuracies for 32-, 8-, 6- and 4-bit variants of backbones evaluated on Series4. ResNet50 and VGG-16 are the most robust network evaluated in our study.
QAT tool
For the analysis above we developed an in-house QAT framework to quantise PyTorch models and successfully map them onto Imagination NNAs. Generality and simplicity are significant advantages of the tool. For QAT we used very similar training hyperparameters across all networks represented in this blog post. With careful fine-tuning we expect that even better performance and accuracies, particularly at low bit depths, can be achieved – this is left as future work.
Conclusions
It is important to choose neural network architectures that maximise performance for a given accuracy. In addition, techniques such as QAT for low-precision inference can be applied that reduce costs further without significantly impacting accuracy. This is particularly important where the target hardware supports low-bit-depth inference, as is the case in Imagination’s Series4 NNAs.
In this blog post, we have identified several networks that give a good trade-off of cost against accuracy at different performance points. Further optimisations, such as exploiting lower bit depth hardware support for integer weights can give a significant boost to performance without harming accuracy.
Bibliography
Chao, Ping, Chao-Yang Kao, Yu-Shan Ruan, Chien-Hsiang Huang, and Youn-Long Lin. 2019. “HarDNet: A Low Memory Traffic Network.” Computer Vision and Pattern Recognition.
Csefalvay, Szabolcs. 2022. Self-Compressing Neural Networks. https://blog.imaginationtech.com/self-compressing-neural-networks.
He, Kaiming, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. 2015. “Deep Residual Learning for Image Recognition.” Computer Vision and Pattern Recognition.
Ping Chao, Chao-Yang Kao, Yu-Shan Ruan, Chien-Hsiang Huang, Youn-Long Lin. 2019. “HarDNet: A Low Memory Traffic Network.” Computer Vision and Pattern Recognition.
Radosavovic, Ilija, Raj Prateek Kosaraju, Ross Girshick, Kaiming He, and Piotr Dollár. 2020. “Designing Network Design Spaces.” Computer Vision and Pattern Recognition.
Sandler, Mark, Andrew Howard, Menglong Zhu, Andrey Zhmoginov, and Liang-Chieh Chen. 2018. “MobileNetV2: Inverted Residuals and Linear Bottlenecks.” The IEEE Conference on Computer Vision and Pattern Recognition.
Simonyan, Karen, and Andrew Zisserman. 2015. “Very Deep Convolutional Networks for Large-Scale Image Recognition.” Computer Vision and Pattern Recognition.
Tan, Mingxing, and Quoc V. Le. 2020. “EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks.” International Conference on Machine Learning.



